
特征工程介绍
特征方程
1、特征方程是什么
是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系
对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
通过总结和归纳,人们认为特征工程包括以下方面:
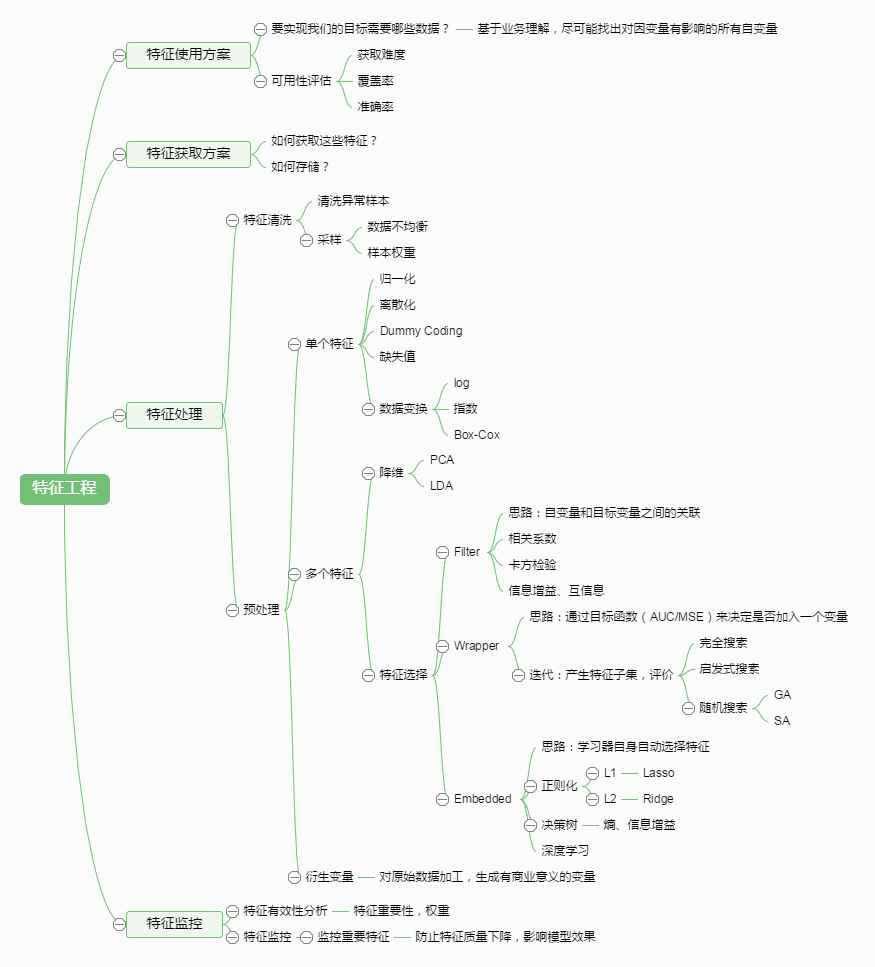
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大!
2、数据预处理
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
作者:城东
链接:https://www.zhihu.com/question/29316149/answer/110159647
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
我们使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
2.1 无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
2.1.1 标准化
标准化需要计算特征的均值和标准差,公式表达为:
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
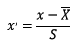
1 | from sklearn.preprocessing import StandardScaler |
2.1.2 区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
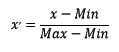
2.1.3 标准化与归一化的区别
**标准化(**StandardizationStandardization):将数据变换为均值为0,标准差为1的分布切记,并非一定是正态的;

归一化(Normalization):将一列数据变化到某个固定区间(范围)中,通常,这个区间是[0, 1],广义的讲,可以是各种区间,比如映射到[0,1]一样可以继续映射到其他范围,图像中可能会映射到[0,255],其他情况可能映射到[-1,1];

使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
1 | from sklearn.preprocessing import Normalizer |
中心化:另外,还有一种处理叫做中心化,也叫零均值处理,就是将每个原始数据减去这些数据的均值。
2.1.4 标准化,归一化的时机差别
如果你对处理后的数据范围有严格要求,那肯定是归一化,个人经验,标准化是ML中更通用的手段,如果你无从下手,可以直接使用标准化;如果数据不为稳定,存在极端的最大最小值,不要用归一化。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化表现更好;在不涉及距离度量、协方差计算的时候,可以使用归一化方法。
2.2 对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:
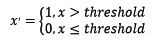
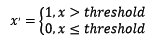
使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
1 | from sklearn.preprocessing import Binarizer |
2.3 对定性特征哑编码
由于IRIS数据集的特征皆为定量特征,故使用其目标值进行哑编码(将离散定性数据转化为数字数据)。使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
1 | from sklearn.preprocessing import OneHotEncoder |
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

2.3.1 独热编码one-hot encoding
one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

2.4 缺失值计算
由于IRIS数据集没有缺失值,故对数据集新增一个样本,4个特征均赋值为NaN,表示数据缺失。使用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
1 | from numpy import vstack, array, nan |
参数说明:
- missing_values :指定何种占位符表示缺失值,可选 number ,string ,np.nan(default) ,None
- strategy :插补策略,字符串,默认"mean"
- “mean” :使用每列的平均值替换缺失值,只能与数字数据一起使用
- “median”:则使用每列的中位数替换缺失值,只能与数字数据一起使用
- “most_frequent” :则使用每列中最常用的值(众数)替换缺失值,可以与字符串或数字数据一起使用
- “constant” :则用 fill_value 替换缺失值。可以与字符串或数字数据一起使用
友情链接:




