
BN层批量归一化
原文链接:https://blog.csdn.net/wjinjie/article/details/118949226
批量归一化问题总结
1、批归一化BN
Batch Normalization是2015年一篇论文中提出的数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。
2、为什么要批归一化BN
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。
要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 σ ( W X + b ) \sigma(WX+b)σ(WX+b) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。
如果我们能在网络的中间也进行归一化处理,那么就能将中间层数据统一到同一量纲。 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
3、BN 计算过程
下面给出 BN 算法在训练时的过程:
输入:上一层输出结果
,学习参数
算法流程:
(1)计算上一层输出数据的均值:
其中,$m $是此次训练样本 batch 的大小。
(2)计算上一层输出数据的标准差
(3)归一化处理,得到:
其中 是为了避免分母为 0 而加进去的接近于 0 的很小值。
(4)重构,对经过上面归一化处理得到的数据进行重构,得到:
其中,$ \gamma, \beta$ 为可学习参数。
4、BN中均值、方差具体怎么计算得到?
神经网络中传递的是张量数据,其维度通常记为【N, H, W, C】,其中 N 是batch_size,H、W是行、列,C是通道数。假设一次送入10张彩色图片进行处理,那么维度是:【10,H,W,3】。
1)均值的计算:
就是在一个批次内(10张),将每张图中的对应通道中的数字加起来,然后求均值。必例如彩色图像有RGB三个通道。所以求均值时,需要计算的是10张图同一通道上的均值。计算过程:将10张图中所有R通道上的像素值加起来,再除以(10xHxW),即得到均值。同理可得。
(2)方差的计算:
根据下式,对RGB三个通道,分别计算方差:
5、训练与推理中BN的区别
训练时,均值、方差分别是该批次内数据相应维度上的均值与方差;训练一旦结束,学习参数gamma和bata也就确定了。
推理时,通常进行一个样本的预测,就并没有batch的概念,因此,这个时候用的是全部训练数据的均值和方差。实际过程中,这种方法比较消耗内存,所以一般通过滑动平均法来求得。
6、归一化的作用(优点)
归一化是深度学习神经网络训练中常用的技巧,它的作用主要在于:
- 统一量纲,使网络层数据呈同一分布,使模型的训练过程更加稳定。
- 加快梯度下降的速度,促使模型快速收敛
- 在一定程度上缓解了深层网络中梯度弥散的问题,从而使训练深层网络模型更加容易(原因是:比如tanh、sigmoid等激活函数,在输入较大或较小时,梯度会出现弥散。而归一化将输入限幅在了0-1之间)
- 重构了原始的数据分布,一定程度上缓解过拟合,防止每批训练中某一个样本经常被挑选到,有助于提高精度。
- 减少了人为选择参数。在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项约束参数。
- 减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛。
- 可以不再使用局部响应归一化。BN 本身就是归一化网络(局部响应归一化在 AlexNet 网络中存在)。
7、批归一化BN适用范围
(1) BN在激活函数之前
在CNN中,BN一般作用在激活函数之前(如下所示,是一个经典的例子)。个人觉得,这是由激活函数的性质决定的。由于像sigmoid、tanh等激活函数,当输入过大或过小时,梯度接近于0,会导致梯度弥散,所以要在激活函数输入之前将数值限制在0-1之间。而对于relu等激活函数几乎不受这种影响,但是在relu函数之前加入BN,经过relu之后输出的数值范围也在0-1之间,因此送入卷积层计算的数值也就在0-1范围之间。
相反,如果在卷积层之前添加BN时,虽然卷积层的输入数据能限制在 0-1 范围之间,但是经过卷积层之后的数据就不一定在0-1 范围之间,就达不到在激活函数之前限幅的目的。
1 | self.listLayers = [self.bn1, |
(2)BN适用场景
在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
BN 在每个 mini-batch 比较大,数据分布比较接近的场景比较适用。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
8、常见的归一化类型
(1)线性归一化
比较适用于在数值比较集中的情况。缺点是如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。线性归一化公式如下:
(2)标准差标准化
使经过处理的数据符合标准正太分布,即均值为 0,标准差为 1。其中 $ \mu$ 为所有样本数据的均值,$ \sigma$ 为所有样本数据的标准差。标准差标准化公式如下:
(3)局部响应归一化
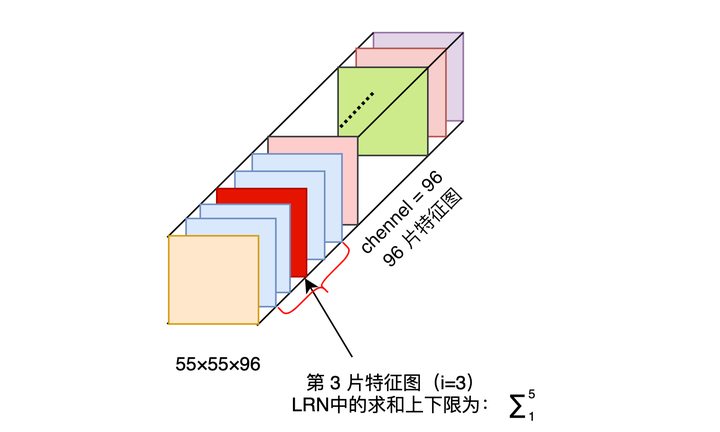
LRN (Local Response Normalization)是一种提高深度学习准确度的技术方法。在 ALexNet 中,提出了 LRN 层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN 一般是在激活、池化函数后使用。
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),其公式如下:
- a 表示卷积层(包括卷积操作和激活操作)后的输出结果。这个输出的结果是一个四维数组 [batch,height,width,channel]。这个输出结构中的一个位置 [a,b,c,d],可以理解成在某一张特征图中的某一个通道下的某个高度和某个宽度位置的点,即第 a 张特征图的第 d 个通道下的高度为 b 宽度为 c 的点。
表示第 i 片特征图在位置(x,y)运用激活函数 ReLU 后的输出。n 是同一位置上临近的 feature map 的数目,N 是特征图的总数。
- 参数
都是超参数。k=2,n=5,α=10-4,β=0.75。
举一个例子:
i = 10, N = 96 时,第 i=10 个卷积核在位置(x,y)处的取值为
除以第 8、9、10、11、12 片特征图位置(x,y)处的取值求和。
也就是跨通道的一个 Normalization 操作。
(4)非线性归一化
非线性归一化经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。
9、BN、LN、IN与GN对比
深度学习中数据的维度一般是【N, H, W, C】格式,其中 N 是batch size,H、W是特征图的高和宽,C是特征图的通道数。如下图所示,是 BN、LN、IN 与 GN 作用方式的对比图。

下面分别来解释这四种不同的归一化方式:
- 批归一化BN:对批次方向(N)做归一化
- 层归一化LN:在通道方向(C)上做归一化,主要对RNN作用明显
- 实例归一化IN:在一个图像像素内做归一化,主要用于风格化迁移
- 组归一化GN:在通道方向上分组,然后再每个组内做归一化
组归一化的优点:组归一化将通道分成组,并在每组内计算归一化的均值和方差。组归一化的计算与批量大小无关,所以其准确度在各种批量大小都很稳定。
10、BN 和 WN 比较
WN(Weight Normalization)是权重归一化,它与BN都属于参数重写的方法,只是采用的方式不同。WN 是对网络权值 W进行归一化, BN 是对网络某一层输入数据进行归一化。
WN 相比 BN 的优势在于:
- 通过重写深度学习网络的权重W的方式来加速深度学习网络参数收敛,没有引入 minbatch 的依赖,适用于 RNN、LSTM网络;而 BN 不能直接用于RNN,原因在于:(1) RNN 处理的 Sequence 是变长的;2) RNN 是基于时间状态 计算,如果直接使用 Batch Normalization 处理,需要保存每个时间状态下mini btach 的均值和方差,效率低且占内存)。
- Batch Normalization 基于一个 mini batch 的数据计算均值和方差,而不是基于整个 Training set 来做,相当于进行梯度计算式引入噪声。因此,Batch Normalization 不适用于对噪声敏感的强化学习、生成模型。相反,Weight Normalization 对通过标量 g 和向量 v 对权重 W 进行重写,重写向量 v是固定的,因此,基于 Weight Normalization 的 Normalization 可以看做比 Batch Normalization 引入更少的噪声。
- 不需要额外的存储空间来保存 mini batch 的均值和方差,同时实现 Weight Normalization 时,对深度学习网络进行正向信号传播和反向梯度计算带来的额外计算开销也很小。因此,要比采用 Batch Normalization 进行 normalization 操作时,速度快。
11、归一化和标准化的联系与区别
- 联系:都能取消由于量纲不同引起的误差;都是一种线性变换;都是对向量按照比例压缩再进行平移。
- 区别:归一化是将样本的特征值转换到同一量纲下,把数据映射到 [0, 1] 或 [-1, 1] 区间内,区间放缩法是归一化的一种。标准化是将样本转换成标准正太分布,使其和整体样本分布相关,每个样本点都能对标准化产生影响。




