时间序列模型
时间序列(按照时间排序的一组随机变量)_百度百科 (baidu.com)
时间序列(ARIMA)案例超详细讲解
1 | 时间序列是按照一定的时间间隔排列的一组数据,其时间间隔可以是任意的时间单位,如小时、日、周月等。通过对这些时间序列的分析,从中发现和揭示现象发展变化的规律,并将这些知识和信息用于预测。 |
想象一下,你的任务是:根据已有的历史时间数据,预测未来的趋势走向。作为一个数据分析师,你会把这类问题归类为什么?当然是时间序列建模。
从预测一个产品的销售量到估计每天产品的用户数量,时间序列预测是任何数据分析师都应该知道的核心技能之一。常用的时间序列模型有很多种,在本文中主要研究ARIMA模型,也是实际案例中最常用的模型,这种模型主要针对平稳非白噪声序列数据。
时间序列概念
时间序列是按照一定的时间间隔排列的一组数据,其时间间隔可以是任意的时间单位,如小时、日、周月等。通过对这些时间序列的分析,从中发现和揭示现象发展变化的规律,并将这些知识和信息用于预测。比如销售量是上升还是下降,是否可以通过现有的数据预测未来一年的销售额是多少等。
构成要素:长期趋势,季节变动,循环变动,不规则变动。
1)长期趋势(T)现象在较长时期内受某种根本性因素作用而形成的总的变动趋势。
2)季节变动(S)现象在一年内随着季节的变化而发生的有规律的周期性变动。
3)循环变动(C)现象以若干年为周期所呈现出的波浪起伏形态的有规律的变动。
4)不规则变动(I)是一种无规律可循的变动,包括严格的随机变动和不规则的突发性影响很大的变动两种类型。
时间数列的组合模型
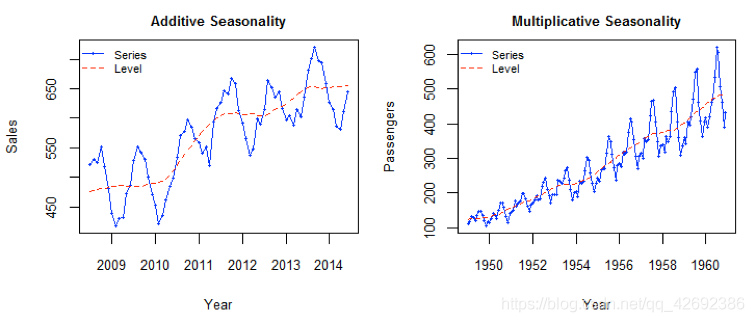
1加法模型:Y=T+S+C+I(Y,T计量单位相同的总量指标)(S,C,I对长期趋势产生的或正或负的偏差)
2乘法模型:Y=T·S·C·I(常用模型)(Y,T计量单位相同的总量指标)(S,C,I对原数列指标增加或减少的百分比)
1 ARIMA(差分自回归移动平均模型)简介
模型的一般形式如下式所示:
1.1 适用条件
数据序列是平稳的,这意味着均值和方差不应随时间而变化。通过对数变换或差分可以使序列平稳。
输入的数据必须是单变量序列,因为ARIMA利用过去的数值来预测未来的数值。
1.2 分量解释
AR(自回归项)、I(差分项)和MA(移动平均项):
AR项是指用于预测下一个值的过去值。AR项由ARIMA中的参数p定义。p值是由PACF图确定的。
MA项定义了预测未来值时过去预测误差的数目。ARIMA中的参数q代表MA项。ACF图用于识别正确的q值
差分顺序规定了对序列执行差分操作的次数,对数据进行差分操作的目的是使之保持平稳。ADF可以用来确定序列是否是平稳的,并有助于识别d值。
1.3 模型基本步骤
1.31 序列平稳化检验,确定d值
对序列绘图,进行 ADF 检验,观察序列是否平稳(一般为不平稳);对于非平稳时间序列要先进行 d 阶差分,转化为平稳时间序列
1.32 确定p值和q值
(1)p 值可从偏自相关系数(PACF)图的最大滞后点来大致判断,q 值可从自相关系数(ACF)图的最大滞后点来大致判断
(2)遍历搜索AIC和BIC最小的参数组合
1.33 拟合ARIMA模型 (p,d,q)
1.34 预测未来的值
2 案例介绍及操作
基于 1985-2021年某杂志的销售量,预测某商品的未来五年的销售量。
2.1 序列平稳化检验,确定d值
平稳性概念
假定某个时间序列是由一系列随机过程生成的,即假定时间序列的每一个数值都是从一个概率分布中随机得到,如果满足下列条件:
均值u是与时间t无关的常数;
方差是与时间t无关的常数;
协方差是只与时间间隔K有关,与时间t无关的常数
则称该随机时间序列是平稳的,而该随机过程是平稳随机过程。
ADF思路
白噪声的过程是:
对于白噪声序列,基本是在均值附近较为平均的随机震荡。它满足正态分布,均值与方差都是与时间t无关的函数,它满足平稳性要求。
随机游走的过程是:
对于随机游走,可以看到比白噪声平滑很多,并且呈现出一些“趋势性”的感觉。它的均值为0,方差与时间t有关,他不满足平稳性要求。
而随机游走的一阶差分是平稳的:
如果一个时间序列是非平稳的,它常常可以通过取差分的方法而形成平稳序列。
ADF 大致的思想就是基于随机游走的,对回归,如果发现p=1,说明序列满足随机游走,就是非平稳的。
下图是通过spsspro软件生成:
如何确定该序列是否平稳呢?
(1)临界值检验
临界值1%、5%、10%不同程度拒绝原假设的统计值和假设检验值t进行比较,t同时小于1%、5%、10%即说明非常好地拒绝该假设
(2)显著性检验p<0.05
本数据中,原序列的 ADF 假设检验值t为1.814, 大于三个level的统计值,所以是非平稳的。而一阶差分序列的 ADF 假设检验值t为-3.156,小于三个level的统计值,再来看显著性p的值为0.023<0.05,所以是平稳的。
经过二阶差分,与一阶差分相比,只是在显著性程度上扩大了,因此对于该序列,采用一阶差分比较合适。一般情况下,采用一阶、二阶差分就可以使序列变得平稳。
所以差分阶数d=1
2.2 确定p值和q值
2.21 绘制ACF 、PACF图
先来介绍几个概念:
拖尾和截尾
拖尾,顾名思义,就是序列缓慢衰减,“尾巴”慢慢拖着滑下来,或者震荡衰减
而截尾则是突然截断了,像个悬崖,指序列从某个时点变得非常小
专业点来说呢,就是:
如果样本自相关系数和样本偏自相关系数在最初的阶明显大于2倍标准差(下图虚线),而后几乎95%的系数都落在2倍标准差的范围内,且非零系数衰减为小值波动的过程非常突然,通常视为k阶截尾。
如果有超过5%的样本相关系数大于2倍标准差,或者非零系数衰减为小值波动的过程比较缓慢或连续,通常视为拖尾。
自相关系数(ACF)
自相关系数度量的是同一事件在两个不同时期之间的相关程度,形象的讲就是度量自己过去的行为对自己现在的影响。在这里可以通过自相关系数(ACF)图的最大滞后点来大致判断q 值。
偏自相关系数(PACF)
计算某一个要素对另一个要素的影响或相关程度时,把其他要素的影响视为常数,即暂不考虑其他要素的影响,而单独研究那两个要素之间的相互关系的密切程度时,称为偏相关。在这里可以通过偏自相关系数(PACF)图的最大滞后点来大致判断p 值。
下图是通过spsspro软件生成:
差分数据自相关图(ACF)
差分数据偏自相关图(PACF)
从上图可以看到:趋势序列 ACF 有 1 阶截尾,PACF 有 1 阶截尾尾。因此可以选 p=1, q=1。
通过拖尾和截尾对模型定阶,具有很强的主观性。
2.22 AIC、BIC准则
AIC 准则全称是最小化信息量准则
其中 L 表示模型的极大似然函数, K 表示模型参数个数。
当样本容量很大时,采用BIC贝叶斯信息准则
其中 n 表示样本容量。
通过比较不同差分阶数的AIC、BIC的值,取两者最小值p、q
从评价准则的结果看:p = 0, q = 1 时,两者值最小,AIC为251.973,BIC为256.724。
2.3 拟合ARIMA模型 (p,d,q)
由上述步骤,我们已知d=1,p=0,q=1,故拟合模型为ARIMA(0,1,1)
采用多元线性回归,得到y(t)=4.996+0.671*ε(t-1)
2.4 预测
使用该公式,得到未来五年的杂志销量分别为285.097、290.093、295.089、300.085、305.081。
3 案例工具实现
3.1使用工具
SPSSPRO—>【预测模型—>时间序列分析(ARIMA)】
3.11 案例操作
Step1:新建分析;
Step2:上传数据;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
step4:选择【时间序列分析(ARIMA)】;
step5:查看对应的数据数据格式,【时间序列分析(ARIMA)】要求输入1个时间序列数据定量变量。
step6:选择向后预测的期数。
step7:点击【开始分析】,完成全部操作。
3.12 分析结果解读
以下生成的结果来源于SPSSPRO软件的分析结果导出,SPSSPRO输出的结果中会给出智能解读结果,直接查看智能分析:
输出结果 1:ADF 检验表
图表说明:该序列检验的结果显示,基于字段年度销量:
在差分为 0 阶时,显著性 P 值为 0.998,水平上不要呈现显著性,不能拒绝原假设,该序列为不平稳的时间序列。在差分为 1 阶时,显著性 P 值为 0.023,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
在差分为 2 阶时,显著性 P 值为 0.000,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
(注意:在理论上,足够多的差分运算可以充分提取原时间序列中的非平稳确定性信息。但进行差分运算需要注意的是,差分运算的阶数不是越多越好。差分是对信息的提取、加工的过程,每次差分都会有信息的损失,所以差分的阶数需要适当,以免过度差分。)
输出结果 2:最佳差分序列图
图表说明:由于一阶差分后序列进行单位根检验的 P 值小于 0.05,说明一阶差分后序列是平稳数据,上图展示了原始数据 1 阶差分后的时序图。
输出结果 3:最终差分数据自相关图(ACF)
图表说明:由自相关图可知,一阶自相关系数很明显地大于 2 倍标准差范围,自一阶自相关系数后,其余自相关系数都在 2 倍标准差范围以内,我们可以判断自相关图为截尾。
输出结果 4:最终差分数据偏自相关图(PACF)
图表说明:由偏自相关图可知,一阶偏自相关系数很明显地大于 2 倍标准差范围,自一阶偏自相关系数后,其余自相关系数都在 2 倍标准差范围以内,我们可以判断偏自相关图为截尾。
输出结果 5:模型参数表
图表说明:由于通过自相关分析和偏自相关分析来判断 ARIMA 的参数存在人为主观性,SPSSPRO 基于 AIC 信息准则自动寻找最优参数,模型结果为 ARIMA 模型(0,1,1)检验表,基于字段:年度销量,从 Q 统计量结果分析可以得到:Q6 在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度 R2 为 0.981,模型表现优秀,模型基本满足要求。(注意:一般来说,只检验前 6 期和前 12 延迟的 Q 统计量(即 Q6 和 Q12)就可得出残差是否是随机序列的结论。这是因为平稳序列通常具有短期相关性,如果一个短期延迟序列值之间不存在显著的相关关系,通常延迟之间就更不会存在显著的相关关系。)
输出结果 6:模型残差自相关图(ACF)
图表说明:上图展示了模型的残差自相关图,(ACF)若相关系数均在虚线(2 倍标准差)内,自回归模型(AR)残差为白噪声序列,时间序列要求模型残差为白噪声序列。很明显,残差的自相关系数均在虚线内。
输出结果 7:模型残差偏自相关图(PACF)
图表说明:上图展示了模型的残差偏自相关图(PACF),若相关系数均在虚线内,滑动平均模型(MA)残差为白噪声序列,时间序列要求模型残差为白噪声序列。很明显,残差的大部分偏自相关系数均在虚线内,即便第 9 阶与第 14 阶超过了 2 倍标准差,这可能是由于偶然因素引起的。
输出结果 8:模型检验表
图表说明:基于字段年度销量,SPSSPRO 基于 AIC 信息准则自动寻找最优参数,模型结果为 ARIMA 模型(0,1,1)检验表且基于 1 差分数据,模型公式如下:y(t)=4.996+0.671*ε(t-1)
输出结果 9:时间序列图
图表说明:上图表示了该时间序列模型的原始数据图、模型拟合值、模型预测值。从图可知,拟合序列趋势与真实序列趋势有着极大的相似性,说明拟合效果较好。
输出结果 10:时间序列预测表
图表说明:上表显示了时间序列模型最近 5 期数据预测情况。
4 结论
ARIMA 是用于单变量时间序列数据预测的最广泛使用方法之一,模型十分简单,只需要内生变量而不需要借助其他外生变量,但是,采用ARIMA模型预测时序,数据必须是稳定的,如果不稳定的数据,是无法捕捉到规律的。比如股票数据用ARIMA无法预测的原因就是股票数据是非稳定的,常常受政策和新闻的影响而波动。
时间序列(一):时间序列数据与时间序列预测模型
朴素法
朴素法就是预测值等于实际观察到的最后一个值。它假设数据是平稳且没有趋势性与季节性的。通俗来说就是以后的预测值都等于最后的值。
这种方法很明显适用情况极少,所以我们重点通过这个方法来熟悉一下数据可视化与模型的评价及其相关代码。
1 | #朴素法 |
得到结果:
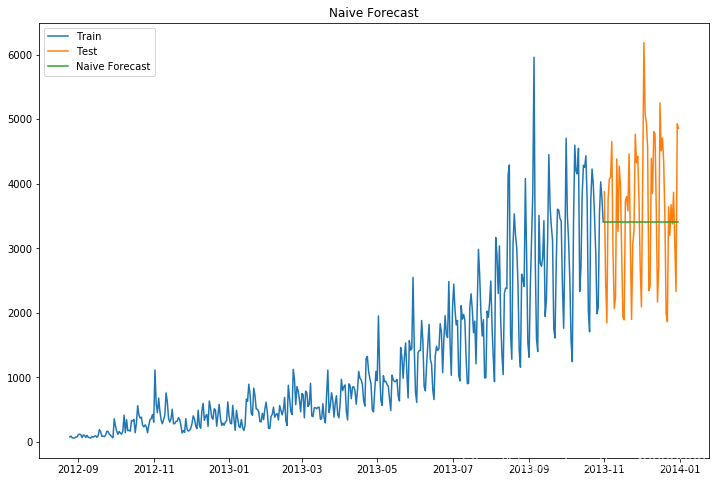
我们通过计算均方根误差,检查模型在测试数据集上的准确率。
其中均方根误差(RMSE)是各数据偏离真实值的距离平方和的平均数的开方
1 | #计算均方根误差RMSE |
得到均方根误差为1053
简单平均法
简单平均法就是预测的值为之前过去所有值的平均.当然这不会很准确,但这种预测方法在某些情况下效果是最好的。
1 | #简单平均法 |
其后续可视化与模型效果评估方法与上述一致,这里不再赘述,需要详细代码可以查看相关源码。得到RMSE值为2637
移动平均法
我们经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。因此,我们只取最近几个时期的价格平均值。很明显这里的逻辑是只有最近的值最要紧。这种用某些窗口期计算平均值的预测方法就叫移动平均法。
1 | #移动平均法 |
其后续可视化与模型效果评估方法与上述一致,这里不再赘述,需要详细代码可以查看相关源码。得到RMSE值为1121
指数平滑法
在做时序预测时,一个显然的思路是:认为离着预测点越近的点,作用越大。比如我这个月体重100斤,去年某个月120斤,显然对于预测下个月体重而言,这个月的数据影响力更大些。
假设随着时间变化权重以指数方式下降——最近为0.8,然后0.82,0.83…,最终年代久远的数据权重将接近于0。将权重按照指数级进行衰减,这就是指数平滑法的基本思想。
指数平滑法有几种不同形式:一次指数平滑法针对没有趋势和季节性的序列,二次指数平滑法针对有趋势但没有季节性的序列,三次指数平滑法针对有趋势也有季节性的序列。“
所有的指数平滑法都要更新上一时间步长的计算结果,并使用当前时间步长的数据中包含的新信息。它们通过”混合“新信息和旧信息来实现,而相关的新旧信息的权重由一个可调整的参数来控制。
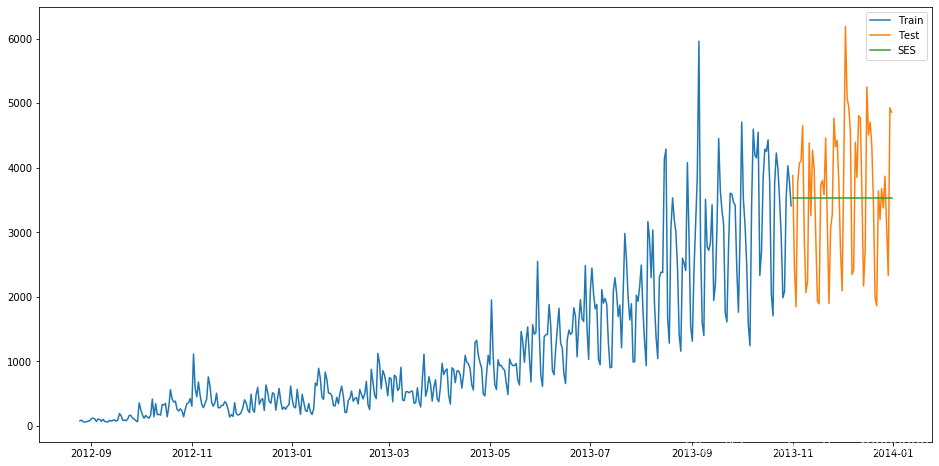
一次指数平滑
一次指数平滑法的递推关系如下:
其中,是时间步长i(理解为第i个时间点)上经过的平滑后的值,是这个时间步长上的实际数据。
可以是0,1之间的任意值,他控制的新旧信息之间的平衡:a接近1保留当前数据点,a接近0时,保留前面的平滑值。其递推关系式:
可以看出,在指数平滑法中,所有先前的观测值都对当前的平滑值产生了影响,但它们所起的作用随着参数 α 的幂的增大而逐渐减小。那些相对较早的观测值所起的作用相对较小。同时,称α为记忆衰减因子可能更合适——因为α的值越大,模型对历史数据“遗忘”的就越快。从某种程度来说,指数平滑法就像是拥有无限记忆(平滑窗口足够大)且权值呈指数级递减的移动平均法。一次指数平滑
si已经是最后一个算出来的值,h等于1代表预测的下一个值。
我们可以通过statsmodels中的时间序列模型进行指数平滑建模。官方文档地址为:
https://www.statsmodels.org/stable/generated/statsmodels.tsa.holtwinters.SimpleExpSmoothing.html
具体代码如下:
1 | #一次指数平滑 |
二次指数平滑(线性回归)
在介绍二次指数平滑前介绍一下趋势的概念。
趋势,或者说斜率的定义很简单b=Δy/Δx,
所以对于一个序列而言,相邻两个点的Δ x = 1 Δx=1Δx=1,因此)b=Δy=y(x)−y(x−1)。 除了用点的增长量表示,也可以用二者的比值表示趋势。比如可以说一个物品比另一个贵20块钱,等价地也可以说贵了5%,前者称为可加的(addtive),后者称为可乘的(multiplicative)。在实际应用中,可乘的模型预测稳定性更佳,但是为了便于理解,我们在这以可加的模型为例进行推导。
指数平滑考虑的是数据的baseline,二次指数平滑在此基础上将趋势作为一个额外考量,保留了趋势的详细信息。即我们保留并更新两个量的状态:平滑后的信号和平滑后的趋势。公式如下:
基准等式:
趋势等式:
第二个等式描述了平滑后的趋势。当前趋势的未平滑“值” ()是当前平滑值()和上一个平滑值的差;
的差;也就是说,当前趋势告诉我们在上一个时间步长里平滑信号改变了多少。要想使趋势平滑,我们用一次指数平滑法对趋势进行处理,并使用参数 β
对()的处理类似于一次平滑指数法中的(),即对趋势也需要做一个平滑,临近的趋势权重大。
为获得平滑信号,我们像上次那样进行一次混合,但要同时考虑到上一个平滑信号及趋势。假设单个步长时间内保持着上一个趋势,那么第一个等式的最后那项就可以对当前平滑信号进行估计。
若要利用该计算结果进行预测,就取最后那个平滑值,然后每增加一个时间步长就在该平滑值上增加一次最后那个平滑趋势:
三次指数平滑
在应用这种算法前,我们先介绍一个新术语。假如有家酒店坐落在半山腰上,夏季的时候生意很好,顾客很多,但每年其余时间顾客很少。因此,每年夏季的收入会远高于其它季节,而且每年都是这样,那么这种重复现象叫做“季节性”(Seasonality)。如果数据集在一定时间段内的固定区间内呈现相似的模式,那么该数据集就具有季节性。
二次指数平滑考虑了序列的基数和趋势,三次就是在此基础上增加了一个季节分量。类似于趋势分量,对季节分量也要做指数平滑。比如预测下一个季节第3个点的季节分量时,需要指数平滑地考虑当前季节第3个点的季节分量、上个季节第3个点的季节分量…等等。详细的有下述公式(累加法):
其中 pi是指“周期性”部分。预测公式如下:
k 是这个周期的长度
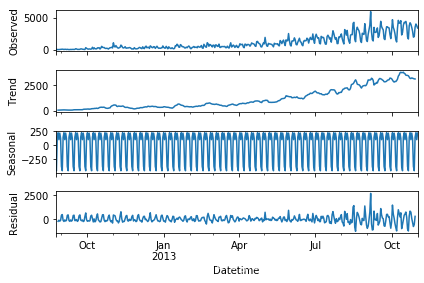
在使用二次平滑模型与三次平滑模型前,我们可以使用sm.tsa.seasonal_decompose分解时间序列,可以得到以下分解图形——从上到下依次是原始数据、趋势数据、周期性数据、随机变量(残差值)
AR模型
AR(Auto Regressive Model)自回归模型是线性时间序列分析模型中最简单的模型。通过自身前面部分的数据与后面部分的数据之间的相关关系(自相关)来建立回归方程,从而可以进行预测或者分析。服从p阶的自回归方程表达式AR§如下:
其中:
- 为白噪声,是时间序列中的数值的随机波动,但是这些波动会相互抵消,最终是0。
- 为自回归系数。
所以当只有一个时间记录点时,称为一阶自回归过程,即AR(1)。其表达式为:$ x_t = \phi x_{t-1} + u_t$
利用Python建立AR模型一般会用到我们之后会说到的ARIMA模型(AR模型中的p是ARIMA模型中的参数之一,只要将其他的参数设置为0即为AR模型)。您可以先阅读后续ARIMA模型的内容并参考文件中的代码查看具体的内容
MA模型
MA(Moving Average Model)移动平均模型通过将一段时间序列中白噪声(误差)进行加权和,可以得到移动平均方程。如下模型为q阶移动平均过程,表示为MA(q)。
其中
-
:t期的值,当期的值由前q期的误差值来决定
-
μ:常数项,相当于普通回归中的截距项
-
μt: 当期的随机误差。
核心思想是每一期的随机误差都会影响当期值,把前q期的所有误差加起来就是对t期值的影响。
同样,利用Python建立MA模型一般会用到我们之后会说到的ARIMA模型,您可以先阅读后续ARIMA模型的内容并参考文件中的代码查看具体的内容
ARMA模型
ARMA(Auto Regressive and Moving Average Model)自回归移动平均模型是与自回归和移动平均模型两部分组成。所以可以表示为ARMA(p, q)。p是自回归阶数,q是移动平均阶数。
从式子中就可以看出,自回归模型结合了两个模型的特点,其中,AR可以解决当前数据与后期数据之间的关系,MA则可以解决随机变动也就是噪声的问题。
ARIMA模型
ARIMA(Auto Regressive Integrate Moving Average Model)差分自回归移动平均模型是在ARMA模型的基础上进行改造的,ARMA模型是针对t期值进行建模的,而ARIMA是针对t期与t-d期之间差值进行建模,我们把这种不同期之间做差称为差分,这里的d是几就是几阶差分。ARIMA模型也是基于平稳的时间序列的或者差分化后是稳定的,另外前面的几种模型都可以看作ARIMA的某种特殊形式。表示为ARIMA(p, d, q)。p为自回归阶数,q为移动平均阶数,d为时间成为平稳时所做的差分次数,也就是Integrate单词的在这里的意思。
SARIMA模型
SARIMA季节性自回归移动平均模型模型在ARIMA模型的基础上添加了季节性的影响,结构参数有七个:SARIMA(p,d,q)(P,D,Q,s)
其中p,d,q分别为之前ARIMA模型中我们所说的p:趋势的自回归阶数。d:趋势差分阶数。q:趋势的移动平均阶数。
P:季节性自回归阶数。
D:季节性差分阶数。
Q:季节性移动平均阶数。
s:单个季节性周期的时间步长数。
时间序列的平稳性、随机性检验
本篇文章我们介绍时间序列的平稳性、随机性检验及相关时间序列数据处理方法。
在拿到时间序列数据后,首先要对数据的随机性和平稳性进行检测, 这两个检测是时间序列预测的重要部分。根据不同检测结果需要采取不同的分析方法。
为什么时间序列要求平稳性呢?
平稳性就是要求由样本拟合出的曲线在未来一段时间内仍然能够以现有的形态和趋势发展下去,这样预测结果才会有意义。
对于平稳声序列, 它的均值和方差是常数, 现已有一套非常成熟的平稳序列的建模方法。 通常是建立一个线性模型来拟合该序列的发展 借此提取该序列的有用信息。
对于非平稳序列, 由于它的均值和方差不稳定, 处理方法一般是将其转变为平稳序列,这样就可以应用有关平稳时间序列的分析方法, 如建立 ARIMA模型来进行相应的研究,或者分解趋势与季节性等并根据情况应用指数平滑模型等。
于它的均值和方差不稳定, 处理方法一般是将其转变为平稳序列,这样就可以应用有关平稳时间序列的分析方法, 如建立 ARIMA模型来进行相应的研究,或者分解趋势与季节性等并根据情况应用指数平滑模型等。
对于纯随机序列, 又称为白噪声序列, 序列的各项之间没有任何相关关系, 序列在进行完全无序的随机波动, 可以终止对该序列的分析。 白噪声序列是没有信息可提取的平稳序列。
在讲解平稳性和随机性的定义之前,我们先介绍一下时间序列中常用的几个特征统计量。
时间序列的特征统计量
对于一个时间序列任意时刻的序列值{Xt,t∈T}{Xt,t∈T}
任意时刻的序列值 X t Xt都是一个随机变量,记其分布函数为 F t ( x ) Ft(x),则其特征统计量均值、方差、自协方差函数、自相关系数的定义分别如下:
均值: 表示时间序列在各个时刻取值的平均值,其定义如下:
方差:表示时间序列在各个时刻围绕其均值波动的平均程度,其定义如下:
**自协方差:**表示时间序列任意两个时刻直接的相关性,任取t,s其定义如下:
**自相关系数:**同自协方差函数,其定义如下:
平稳时间序列的定义与检验
严平稳时间序列: 指时间序列的所有统计性质不会随着时间的推移而发生变化,即其联合概率分布在任何时间间隔都是相同的。
宽平稳时间序列: 宽平稳时间序列则认为只要时间序列的低阶距(二阶)平稳,则该时间序列近似平稳。 应该如何对其进行平稳性的检验呢?目前,对时间序列的平稳性检验主要有两种方法,一种是图检法,即根据时序图和自相关图进行直观判断,另一种是构造检验统计量的方法,有单位根检验法等方法。
- 图检法
- 统计检验法
- ADF检验
后进行平稳化操作。去看博客吧吐了,。