
欠拟合过拟合
过拟合和欠拟合在日常训练模型中一定会遇见。那么它产生的原因是什么?又该如何解决?面试时又该如何回答?
1 过拟合和欠拟合是什么
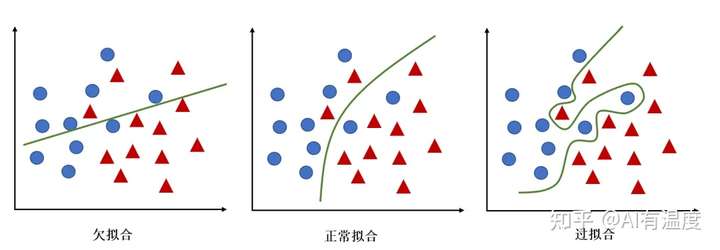
- 拟合(Fitting):模型能不能很好的描述某些样本,并且有比较好的泛化能力
- 过拟合(Overfitting):就是太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测/区分了所有的数据,但是在新的测试集上却表现平平,不具泛化性,拿到新样本后没有办法去准确的判断
- 欠拟合(UnderFitting):测试样本的特性没有学到,或者是模型过于简单无法拟合或区分样本
2 过拟合
2.1 过拟合的表现
当模型在测试集上的损失函数值出现先下降后上升,那么此时可能出现过拟合。
2.2 导致过拟合的原因是什么?
- 训练集数量不足,样本类型单一。例如:如果我们用只包含负样本的训练集训练模型,然后用训练好的模型预测验证集中的正样本时,模型就会在训练时效果特别好,但是在验证时表现很差。因此,在选取训练集尽可能的覆盖所有数据类型。
- 训练集中存在噪声。使得机器将噪声认为是特征,从而忽略了样本的正确特征信息。
- 模型复杂度过高。当模型过于复杂时,会导致模型过于充分的学习到训练数据集中特征信息,将数据“死记硬背”了下来,遇到没见过的数据不能够变通,泛化能力太差。
2.3 过拟合的解决方法是什么?
- 尽可能的保证数据分布均匀,有条件的话可以增加数据量。
- 分析噪声数据,对数据进行清洗。
- 降低模型的复杂度,减少参数、使模型变的简单。
- 在训练过程中使用正则化技术,如Dropout、L1、L2正则化等。
- 交叉验证,将数据切分组合为不同的训练集和测试集,使模型得到充分的训练。
- Early stopping,在模型迭代训练时候记录训练损失值。当训练误差一直在降低但是验证误差却不再降低甚至上升,这时候便可以结束模型训练了。
3 欠拟合
3.1 过拟合的表现
模型无法很好的拟合数据,导致训练集和测试集效果都不佳。
3.2 导致欠拟合的原因是什么?
- 数据特征表达能力不强或者现有特征与标签之间的相关性不强。
- 模型太简单,导致无论怎么学习都无法学到有效的信息,即模型“先天不足”。
- 模型合适,但是没有训练好,即模型还没有训练到收敛的情况。
3.3 欠拟合的解决方法是什么?
- 特征工程。对数据维度进行筛选,选取特征与标签之间关联性强的维度进行建模,同时可去除噪声数据。
- 增加模型复杂度。
- 增加模型训练时间,直到模型收敛为止。
- 减小正则化系数。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 CJH's blog!




