一、前言
泰坦尼克号作为Kaggle经典项目,被拿来做考核或者实验非常多,也是机器学习入门的一个很好的项目。我们机器学习的老师也是直接用这个项目来做考核。
他分工分成了数据处理、模型搭建、PPT制作和文档制作,但是鄙人认为,数据处理与模型搭建密不可分的,比如说在决策树模型中,是不在乎数据实际差值的,但是SVM逻辑回归等算法,如果不用较好的数据变换,基本是没准确度的。
基本上数据处理用了2个小时基本就搞定了,也参考了很多别人的题解,不过我都是自己再写了一遍,代码量不大很好处理。模型搭建其实也就是调用一下sklearn库,我自己认为对于这种比较难以估计的真实情况,而且数据特征、样本量都比较少。把注意力花在调参上,没有什么大的突破。所以我只是为了学习操作流程,把各个模型拿出来,意思意思过一下罢了。菜不行,再怎么烹饪,也煮不出东西来。
本质上这个项目,就是一个入门项目,学习机器学习/数据挖掘的一个过程。差不多得了hhhh。
二、环境搭建
本次实验使用的是
window11(操作系统)
python 3.9(python语言)
jupyter notebook(编辑器很方便)
copy(用来复制内容)
numpy(数组处理)
pandas(数据处理和数据分析)
matplotlib(数据可视化)
seaborn(热力图)
sklearn(机器学习库)
xgboost(机器学习的其中一个模型)
lightgbm(机器学习的其中一个模型)
1 2 3 4 5 6 7 8 9 10 11 12 13 import os import sysimport pandas as pdimport numpy as npimport seaborn as snsimport copyfrom matplotlib import pyplot as pltfrom sklearn.impute import SimpleImputerfrom sklearn import preprocessingfrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitfrom sklearn import metrics
详细可参考:
Anaconda安装
jupyter notebook安装
按着这些教程来就可以了,如果能会用虚拟环境更好,在base环境下跑代码也行,因为用的库对版本要求不大。各种库只需要pip install xxx 就可以了。
三、项目介绍
比赛平台:Titanic - Machine Learning from Disaster | Kaggle
泰坦尼克号的沉没是历史上最臭名昭著的沉船事件之一。
1912年4月15日,在她的处女航中,被广泛认为是 "不沉的 "泰坦尼克号在与冰山相撞后沉没。不幸的是,没有足够的救生艇供船上所有人使用,导致2224名乘客和船员中的1502人死亡。
虽然幸存下来有一定的运气成分,但似乎有些人群比其他人群更有可能幸存下来。
在这项挑战中,我们要求你建立一个预测模型来回答这个问题。"什么样的人更有可能生存?"使用乘客数据(即姓名、年龄、性别、社会经济阶层等)。
主要是介绍了具体项目背景,以及所给train 、 test 数据集中,各个特征的具体含义,我们将在下文进行分析、总结。
四、数据分析
可以使用SPSSPRO 和python的可视化工具进行观察。
我这里强烈建议使用SPSSPRO,当然也会介绍一下python的用法。
由于数据处理前后数据特征会发生变化,我们将使用python数据处理前的数据观察,使用SPSSPRO进行数据处理后的观察。
4.1 数据解释(官方)
survival:是否生存
pclass:船票等级。(社会经济地位(SES)的代表)
1 = 1st:最高级的船票
2 = 2nd:第二级的船票
3 = 3rd:第三级的船票
Sex:性别
Age:年龄(若年龄为0.5,则其为预测的值,不影响数据分布)
sibsp:在泰坦尼克号上的兄弟姐妹/配偶的数量。
parch:在泰坦尼克号上的父母/子女的数量
ticket: 船票号(如果船票号一样,可以说明是同行的人)
fare: 票价。
cabin:机舱号
embarked : 上岸的港口(可以表现社会地位??)
C = Cherbourg
Q = Queenstown
S = Southampton
数据解释网址kaggle
4.2 python 数据观察
4.2.1 导入数据处理库和数据集
1 2 3 4 5 6 7 8 9 10 import pandas as pdimport numpy as npimport seaborn as snsfrom matplotlib import pyplot as plttrain_data = pd.read_csv('train.csv' ) test_data = pd.read_csv('test.csv' ) df = train_data
4.2.2 数据初步观察
1 2 3 4 5 6 7 train_data.info() print ()test_data.info() print ()df.describe(include="all" )
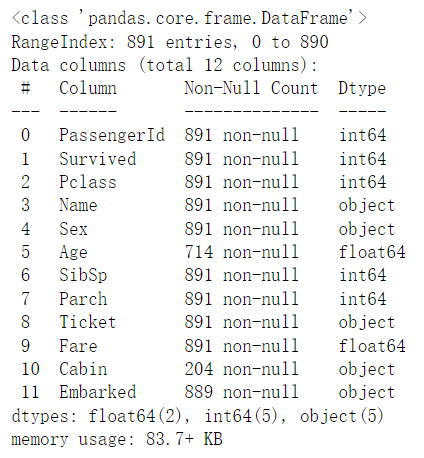
train_data.info()结果:
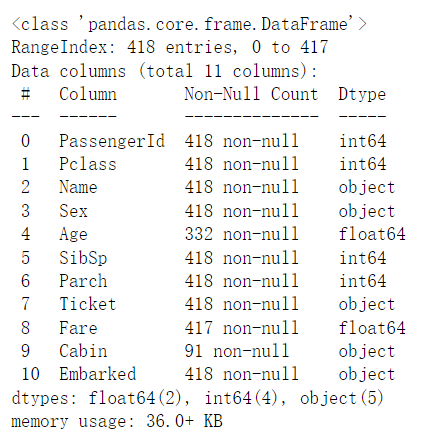
test_data.info()结果:
观察发现,其实test数据集只是少了’Survived’这一特征,我们后续对数据处理以train为主要对象,再对test处理,避免代码冗杂。
同时能得到所有特征的数据类型,object是字符串的意思,对于字符串来说其实对机器学习模型不大友好,基本都是要转定量标准,我们还发现’Age’和‘'Cabin’有一定程度的数据丢失,我们考虑在后续进行处理。
训练集样本量为891,这对于机器学习中,算是比较小的样本量了。对于需要大规模进行数据训练的模型需要谨慎使用。
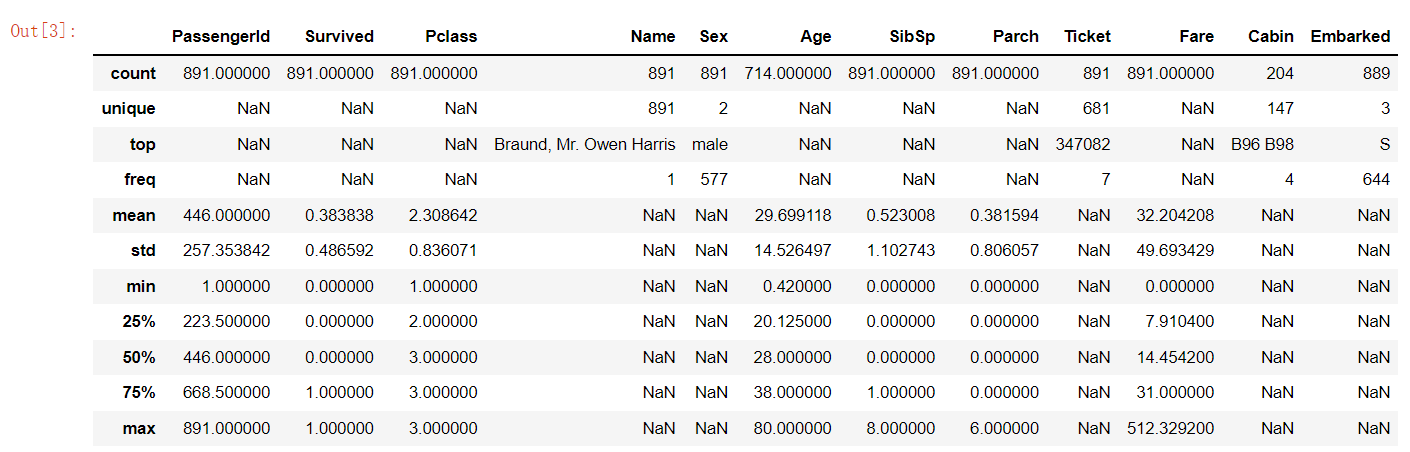
describe结果:
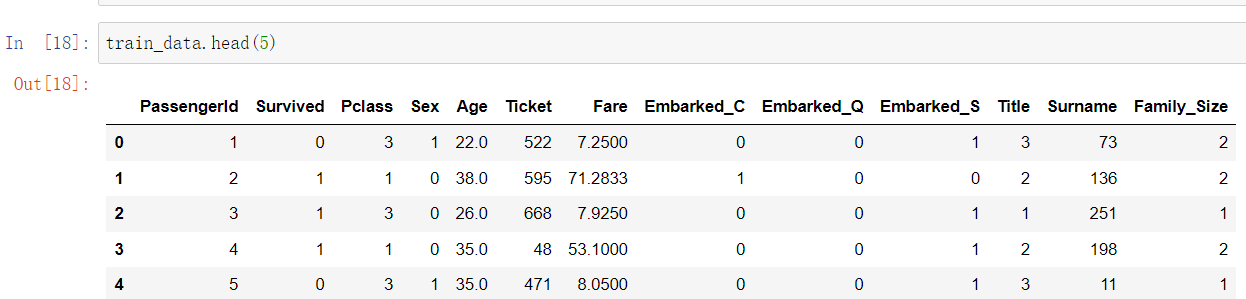
展示训练集的前五行:
4.2.3 python数据可视化
我们先根据启发式算法,也就是生活尝试,判断一下哪些特征可能会跟生存率有影响,我的理解是
[性别、年龄、票价、船舱等级]这几类容易影响,总之画画图啥的,试试看。
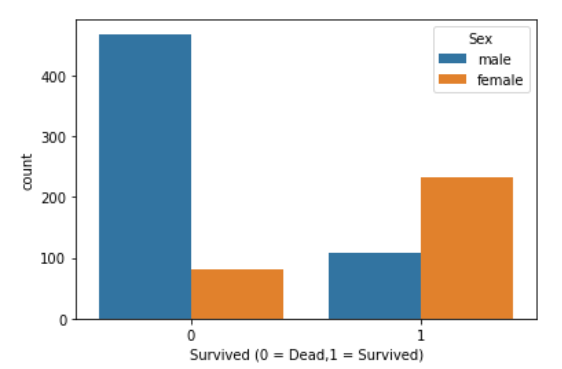
统计生还人数:
1 2 3 Survived=df.groupby('Survived' ).count() Survived
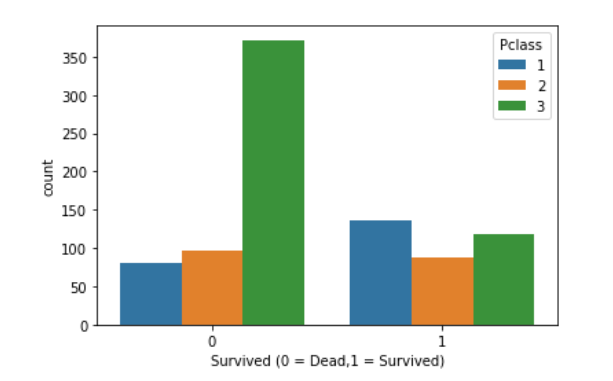
1 2 3 4 sns.countplot(data=df, x ='Survived' , hue = 'Sex' ) plt.xlabel('Survived (0 = Dead,1 = Survived)' )
1 2 3 4 5 sns.countplot(x="Survived" , hue="Pclass" , data=df) plt.xlabel('Survived (0 = Dead,1 = Survived)' )
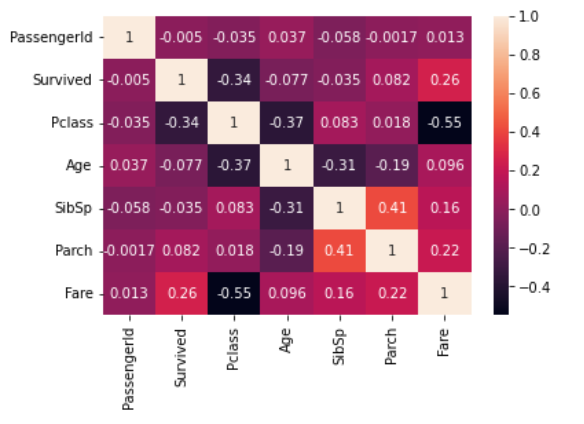
1 2 3 sns.heatmap(df.corr(), annot=True ) plt.show()
通过上面的热图,我们很容易看到正相关最强的特征(橙色)和负相关最强的特征(黑色)
SibSp(堂兄弟)和Parch之间有很强的正相关关系——孩子通常有兄弟姐妹,父母和孩子经常一起旅行
Pclass(船舱等级)和票价之间存在很强的负相关关系——头等舱的机票比下等舱的机票更贵,这意味着当票价越低(接近1),票价就越高
年龄和Pclass(船舱等级)呈中度负相关——富人通常年龄较大
五、数据处理
5.1 异常值处理
1 2 3 4 5 6 7 8 9 10 11 12 train_data = train_data.drop(['Cabin' ],axis=1 ) train_data.dropna(inplace=True ,axis=0 ,subset=['Embarked' ]) train_data.Age.fillna(train_data.Age.mean(),inplace=True ) train_data.info()
5.2 定性数据处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 train_data['Sex' ] = train_data['Sex' ].replace({'female' :0 ,'male' :1 }) a = ['Embarked' ] c = pd.get_dummies(train_data['Embarked' ]) del (train_data['Embarked' ])train_data = pd.concat([train_data,c],axis=1 ) train_data.rename(columns={'C' :'Embarked_C' ,'Q' :'Embarked_Q' ,'S' :'Embarked_S' },inplace=True ) le = LabelEncoder() object_columns = train_data.select_dtypes(include=["object" ]).columns train_data[object_columns] = train_data[object_columns].apply(le.fit_transform)
5.3 数据扩展
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def variables (df ): df['Title' ] = df['Name' ].apply(lambda x : x.split(' ' )[1 ].strip('123,./!?' )) df['Surname' ] = df['Name' ].apply(lambda x : x.split(',' )[0 ]) df.drop('Name' , axis = 1 , inplace = True ) df['Title' ] = df['Title' ].apply(lambda x : x if x in ['Mr' ,'Miss' ,'Mrs' ,'Master' ] else 'NoTitle' ) df['Family_Size' ] = df['SibSp' ] + df['Parch' ] + 1 df['Title' ] = df['Title' ].map ({'NoTitle' : 0 , 'Miss' : 1 , 'Mrs' : 2 ,'Mr' :3 ,'Master' : 4 }) variables(train_data) del (train_data['SibSp' ])del (train_data['Parch' ])
5.4 最终数据集展示和导出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 train_data_true = train_data.copy() train_data = test_data train_data_ID = train_data['PassengerId' ] train_data = train_data.drop(['PassengerId' ],axis=1 ) train_data = train_data.drop(['Cabin' ],axis=1 ) train_data = train_data.fillna(train_data.mean()) train_data['Sex' ] = train_data['Sex' ].replace({'female' :0 ,'male' :1 }) train_data['Sex' ] = train_data['Sex' ].replace({'female' :0 ,'male' :1 }) a = ['Embarked' ] c = pd.get_dummies(train_data['Embarked' ]) del (train_data['Embarked' ])train_data = pd.concat([train_data,c],axis=1 ) train_data.rename(columns={'C' :'Embarked_C' ,'Q' :'Embarked_Q' ,'S' :'Embarked_S' },inplace=True ) def variables (df ): df['Title' ] = df['Name' ].apply(lambda x : x.split(' ' )[1 ].strip('123,./!?' )) df['Surname' ] = df['Name' ].apply(lambda x : x.split(',' )[0 ]) df.drop('Name' , axis = 1 , inplace = True ) df['Title' ] = df['Title' ].apply(lambda x : x if x in ['Mr' ,'Miss' ,'Mrs' ,'Master' ] else 'NoTitle' ) df['Family_Size' ] = df['SibSp' ] + df['Parch' ] + 1 df['Title' ] = df['Title' ].map ({'NoTitle' : 0 , 'Miss' : 1 , 'Mrs' : 2 ,'Mr' :3 ,'Master' : 4 }) variables(train_data) le = LabelEncoder() object_columns = train_data.select_dtypes(include=["object" ]).columns train_data[object_columns] = train_data[object_columns].apply(le.fit_transform) test_data = train_data train_data =train_data_true del (test_data['SibSp' ])del (test_data['Parch' ])test_data.to_csv('test_new.csv' ,index = None ) train_data.to_csv('train_new.csv' ,index = None )
六、模型搭建
表面模型搭建,其实就是套一套用一用,如果想了解具体算法的原理和效果,请参考我的其他博客,在机器学习或数据挖掘标签下基本都有。
6.1 模型数据切割
1 2 3 4 5 6 7 8 train_data =train_data.drop(['PassengerId' ],axis=1 ) data_target_part = train_data['Survived' ] data_features_part = train_data[[x for x in train_data.columns if x != 'Survived' ]] x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2 , random_state = 0 )
6.2 导入XGBoost库(未调参)
1 2 3 4 5 6 7 from xgboost.sklearn import XGBClassifierclf = XGBClassifier() clf.fit(x_train, y_train)
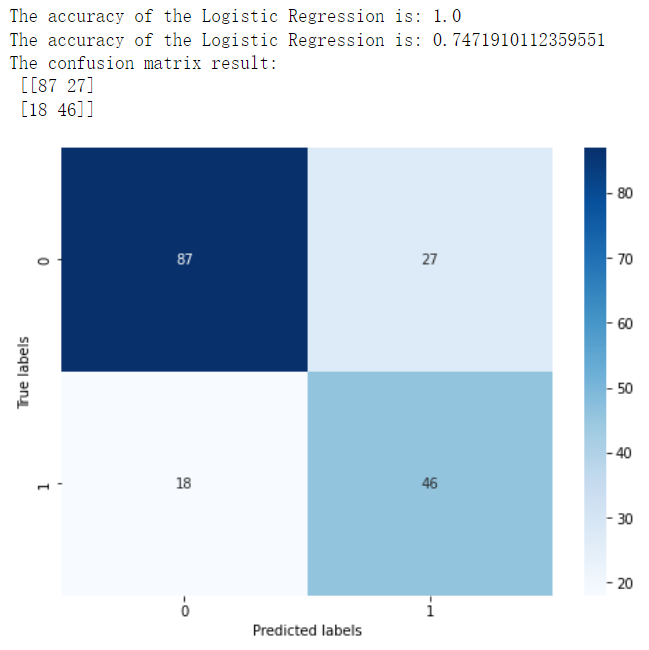
6.3 训练模型、评价模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metricsprint ('The accuracy of the Logistic Regression is:' ,metrics.accuracy_score(y_train,train_predict))print ('The accuracy of the Logistic Regression is:' ,metrics.accuracy_score(y_test,test_predict))confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print ('The confusion matrix result:\n' ,confusion_matrix_result)plt.figure(figsize=(8 , 6 )) sns.heatmap(confusion_matrix_result, annot=True , cmap='Blues' ) plt.xlabel('Predicted labels' ) plt.ylabel('True labels' ) plt.show()
结果如下:
6.3 预测结果
1 2 3 4 5 6 7 8 test_predict = clf.predict(test_data) test_predict = {'PassengerId' : pd.Series(train_data_ID), 'Survived' : pd.Series(test_predict)} test_predict = pd.DataFrame(test_predict) test_predict.to_csv("Submission_xgboost.csv" ,index=None )
七、SPSSPRO数据可视化
7.1 重要特征图表
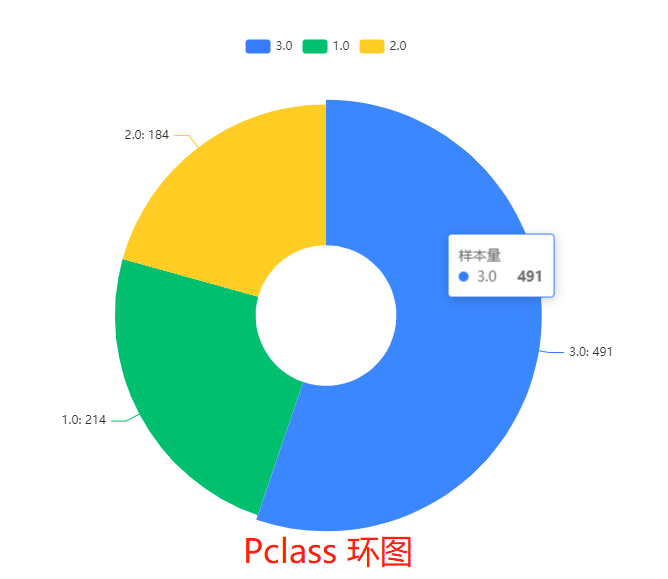
7.1.1 Pclass 环图
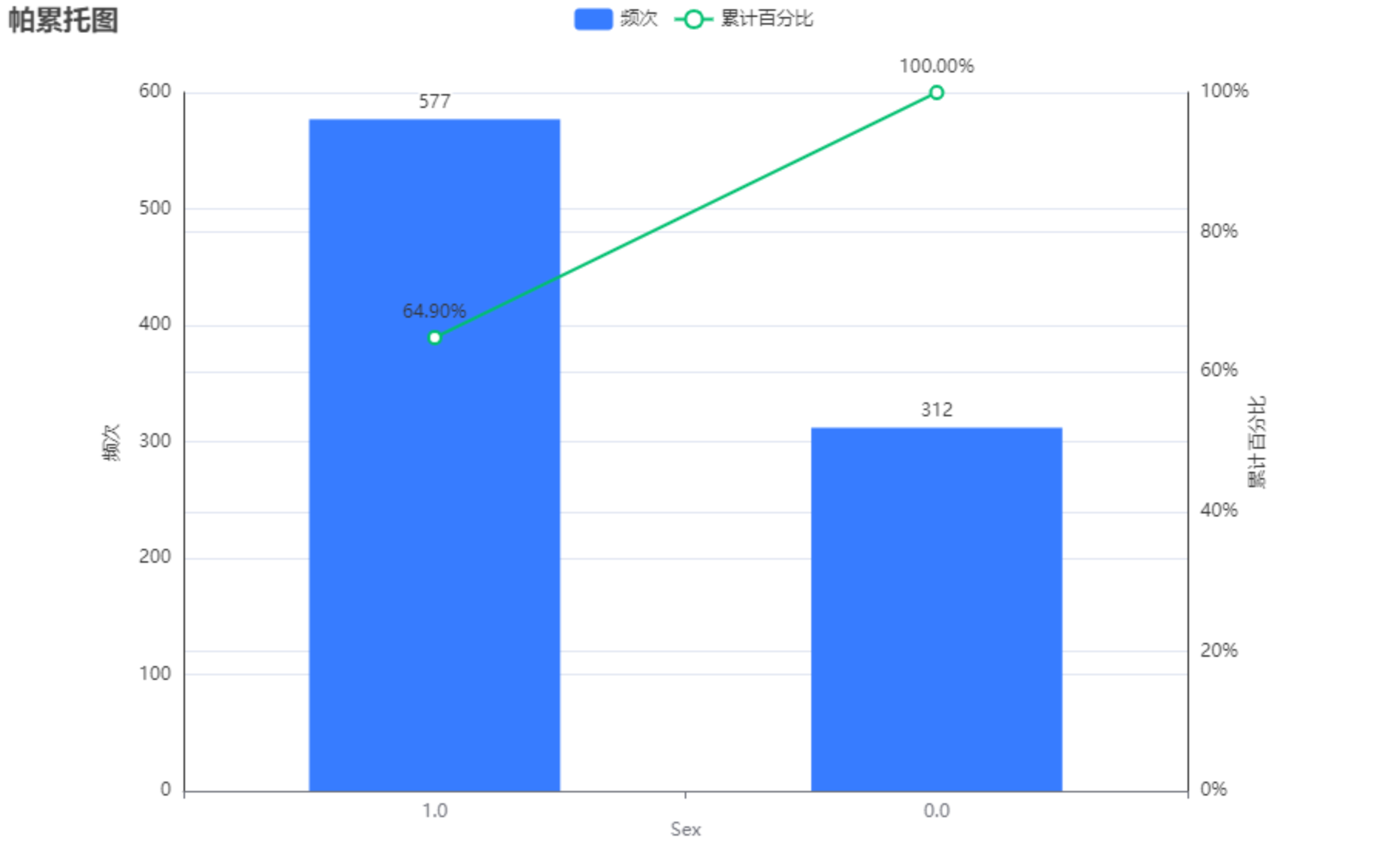
7.1.2 Sex 帕累托图
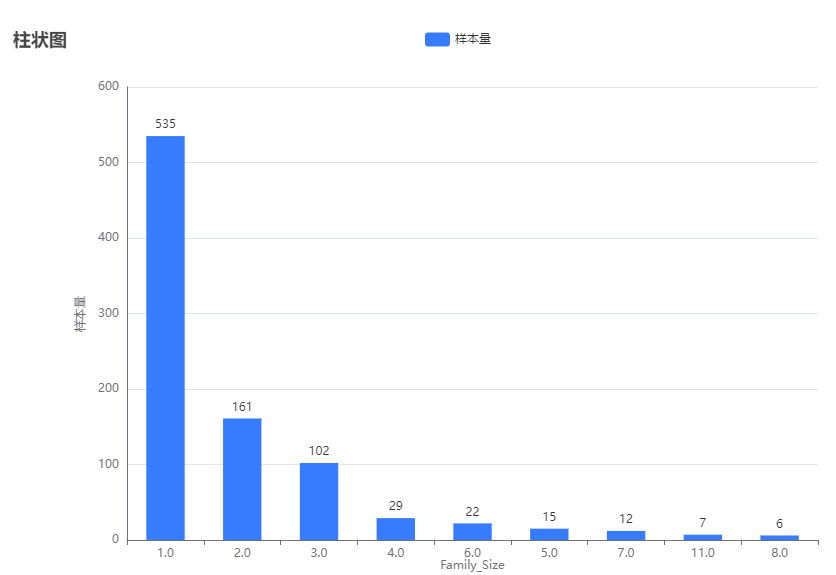
7.1.3 Family_Size 柱状图
大部分都是single all the way 嘻嘻嘻。
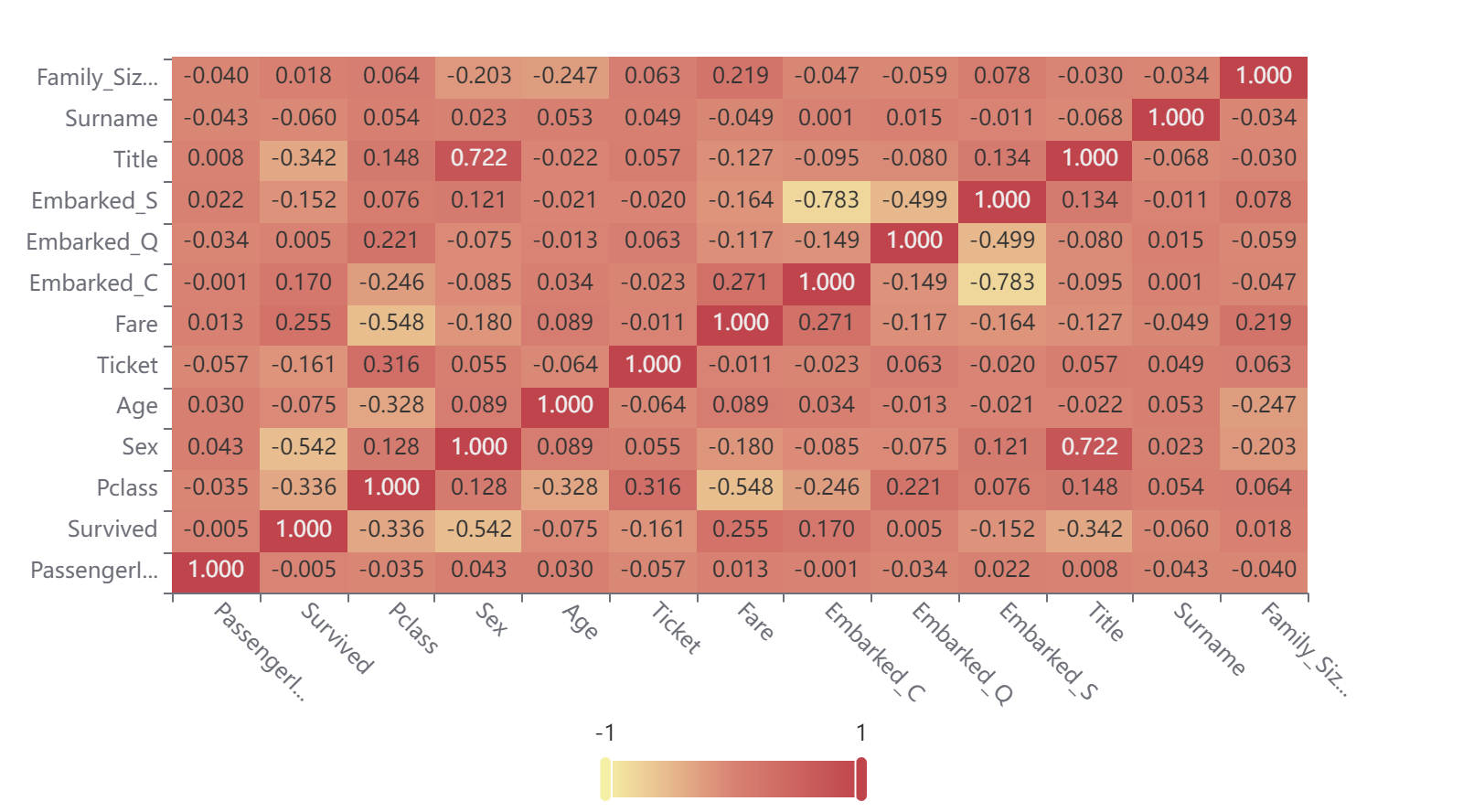
7.2 相关热力图
相关性较强的,Sex,Fare ,Pclass,Title(Title的原因是因为性别相关)。
八、其余算法和答案生成
8.1 全0全1的生成
1 2 3 4 5 6 7 8 9 10 11 allone = {'PassengerId' : pd.Series(train_data_ID), 'Survived' : pd.Series(np.ones((418 ),dtype=int ))} allone = pd.DataFrame(allone) allone.to_csv("allone.csv" ,index=None ) allzeros = {'PassengerId' : pd.Series(train_data_ID), 'Survived' : pd.Series(np.zeros((418 ),dtype=int ))} allzeros = pd.DataFrame(allzeros) allzeros.to_csv("allzeros.csv" ,index=None )
8.2 性别区分
1 2 3 4 5 6 7 8 9 10 11 12 13 sex_predict = [] for i in range (0 ,len (test_data)): if test_data['Sex' ][i] == 1 : sex_predict.append(0 ) else : sex_predict.append(1 ) test_predict = {'PassengerId' : pd.Series(train_data_ID), 'Survived' : pd.Series(np.array(sex_predict))}test_predict = pd.DataFrame(test_predict) test_predict.to_csv("Submission_sex.csv" ,index=None )
8.3 一大堆算法的调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from sklearn.ensemble import AdaBoostClassifierclf_Ada = AdaBoostClassifier(random_state=0 ) from sklearn.tree import DecisionTreeClassifierclf_Tree = DecisionTreeClassifier(random_state=0 ) from sklearn.neighbors import KNeighborsClassifierclf_KNN = KNeighborsClassifier() from sklearn.svm import SVCclf_svm = SVC(random_state=0 ) from sklearn.linear_model import LogisticRegressionclf_log = LogisticRegression(random_state=0 ) from sklearn.ensemble import RandomForestClassifierclf_forest = RandomForestClassifier(random_state=0 ) from sklearn.ensemble import GradientBoostingClassifierclf_gbdt = GradientBoostingClassifier(random_state=0 ) from lightgbm.sklearn import LGBMClassifierclf_lightgbm = LGBMClassifier()
一个个写代码很麻烦,我弄了一个函数用来自定义跑,不过缺点就是没得调参咯。所以准确率差强人意。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def fuckyou (clf,name,train_data,test_data ): data_target_part = train_data['Survived' ] data_features_part = train_data[[x for x in train_data.columns if x != 'Survived' ]] x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2 , random_state = 500 ) clf.fit(x_train, y_train) train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) print ('The accuracy of the Logistic Regression is:' ,metrics.accuracy_score(y_train,train_predict)) print ('The accuracy of the Logistic Regression is:' ,metrics.accuracy_score(y_test,test_predict)) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print ('The confusion matrix result:\n' ,confusion_matrix_result) plt.figure(figsize=(8 , 6 )) sns.heatmap(confusion_matrix_result, annot=True , cmap='Blues' ) plt.xlabel('Predicted labels' ) plt.ylabel('True labels' ) plt.title(name) plt.show() test_predict = clf.predict(test_data) test_predict = {'PassengerId' : pd.Series(train_data_ID), 'Survived' : pd.Series(test_predict)} test_predict = pd.DataFrame(test_predict) test_predict.to_csv("Submission_{}.csv" .format (name),index=None )
运行操作:
1 2 3 4 5 6 7 8 fuckyou(clf_Ada,'Ada' ,train_data,test_data) fuckyou(clf_Tree,'Tree' ,train_data,test_data) fuckyou(clf_svm,'svm' ,train_data,test_data) fuckyou(clf_log,'log' ,train_data,test_data) fuckyou(clf_KNN,'KNN' ,train_data,test_data) fuckyou(clf_forest,'forest' ,train_data,test_data) fuckyou(clf_gbdt,'gbdt' ,train_data,test_data) fuckyou(clf_lightgbm,'lightgbm' ,train_data,test_data)
8.4 集成学习?的尝试
原理:使用多个算法进行预测,如果不同蒜贩预测结果为1的数量多于预测结果为0的数量,则认为最终结果为1.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 data_forest = pd.read_csv('Submission_forest.csv' ) data_lightgbm = pd.read_csv('Submission_lightgbm.csv' ) data_gbdt = pd.read_csv('Submission_gbdt.csv' ) data = data_forest['Survived' ] + data_lightgbm['Survived' ] + data_gbdt['Survived' ] data.replace(1 ,0 ,inplace = True ) data.replace(2 ,1 ,inplace = True ) data.replace(3 ,1 ,inplace = True ) data_connect3 = pd.concat([data_forest['PassengerId' ],data],axis=1 ) data_connect3.to_csv("Submission_connect3.csv" ,index=None ) data_forest = pd.read_csv('Submission_forest.csv' ) data_lightgbm = pd.read_csv('Submission_lightgbm.csv' ) data_gbdt = pd.read_csv('Submission_gbdt.csv' ) data_xgboost = pd.read_csv('Submission_xgboost.csv' ) data_Tree = pd.read_csv('Submission_Tree.csv' ) data = data_forest['Survived' ] + data_lightgbm['Survived' ] + data_gbdt['Survived' ] + data_xgboost['Survived' ] + data_Tree['Survived' ] data.replace(1 ,0 ,inplace = True ) data.replace(2 ,0 ,inplace = True ) data.replace(3 ,1 ,inplace = True ) data.replace(4 ,1 ,inplace = True ) data.replace(5 ,1 ,inplace = True ) data_connect5 = pd.concat([data_forest['PassengerId' ],data],axis=1 ) data_connect5.to_csv("Submission_connect5.csv" ,index=None )
九、最终结果
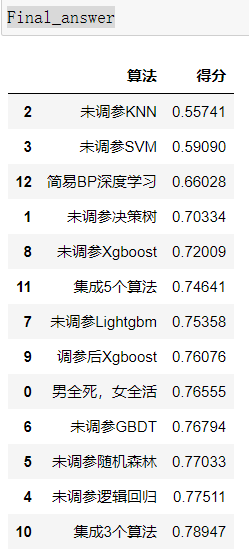
1 2 3 4 5 6 7 8 9 10 x = ['男全死,女全活' ,'未调参决策树' ,'未调参KNN' ,'未调参SVM' ,'未调参逻辑回归' ,'未调参随机森林' ,'未调参GBDT' ,'未调参Lightgbm' ,'未调参Xgboost' ,'调参后Xgboost' ,'集成3个算法' ,'集成5个算法' ,'简易BP深度学习' ] y = [0.76555 ,0.70334 ,0.55741 ,0.59090 ,0.77511 ,0.77033 ,0.76794 ,0.75358 ,0.72009 ,0.76076 ,0.78947 ,0.74641 ,0.66028 ] Final_answer = {'算法' : pd.Series(x), '得分' : pd.Series(y)} Final_answer = pd.DataFrame(Final_answer) Final_answer = Final_answer.sort_values(by=['得分' ]) Final_answer.to_csv('Final_answer.csv' ,index = None ) Final_answer
结果如下:
十、优缺点及改良推广
10.1 优点
数据分析的很全面
考虑到很多算法的使用
有较多的可视化分析
备注很多,易于阅读
10.2 缺点
没有进行模型的解释,对模型学习较无力
没有进行调参,有明显的成绩提升空间
10.3 改良推广
根据SPSS的热力图,Title 应该删去,因为与SEX过于相关。
以XGBoost为首的随机森林模型效果优良。可以考虑从这方面进行调参。