1 前言
豆瓣作为爬虫手们的入手网站,十分的受欢迎。这次我使用xpath这个简单的技术进行爬取。目的就是为了给数据库大作业–图书管理系统做铺垫。本次代码大概花了我4个小时,主要是中间处理数据的时候失误了,有时是标点错误,以及忘记错误处理这种好方法,最终我们爬取了将近12000本书,处理之后得到6983本书,足够我们使用。
使用工具如下:
windows 11
python 3.9
Microsoft Edge
pandas(数据处理)
math(数学计算)
time(时间库,休眠用防封IP)
requests(请求库)
lxml.etree(html文本转化)
所爬取网站(按顺序)为:
豆瓣图书标签 (douban.com)
豆瓣图书标签: 小说 (douban.com)
2 引入相关库
1 2 3 4 5 6 7 8 9 import requests from lxml import etreeimport pandas as pdimport mathimport timeheaders = {'User-Agent' : 'User-Agent:Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50' , 'Referer' : 'https://book.douban.com/tag' }
3 爬取标签
首先我们需要先观察豆瓣网站的网页结构。
操作如下:
1、进入网站豆瓣图书标签 (douban.com)
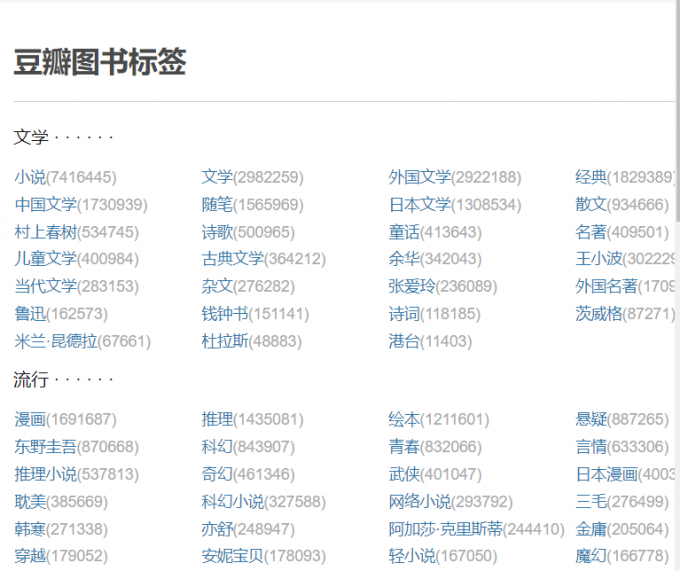
2、使用‘F12’打开开发者工具。网站样式如下:
我们需要按照大的标题 文学,流行,之后爬取小的标题,一行4个以下,且最好把括号内,书的个数也爬了,后面可以改善爬书的个数,就不会不平等。
3、使用crtl + shirt + c 或者点击开发者工具左上角的小爬取标签。
之后你的光标就可以点击你想爬取的内容,在左侧开发者工具栏中,就会跳转到对应的元素代码。
4、根据html排版,找到具体内容。进行爬取,对其右键 复制元素 完整的 xpath路径。
你也可以先使用xpath函数,先往前推进一部分html代码。
具体xpath如何使用,请看:
爬虫之Xpath便捷获取页面元素_猿心不灭的博客-CSDN博客_xpath提取元素
得到代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def get_categories (url,headers ): res = requests.get(url,headers=headers) html = res.text xp = etree.HTML(html) lis = xp.xpath('/html/body/div[3]/div[1]/div/div[1]/div[2]' ) big_categories = [] for li in lis: for i in range (0 ,6 ): a = li.xpath('div/a/h2/text()' )[i].strip().replace("·" ,"\t" ).split("\t" )[0 ] big_categories.append(a) small_categories = [] small_categories_num = [] for li in lis: for i in range (1 ,7 ): tr_len = len (li.xpath('div[{0}]/table/tbody/tr' .format (i))) for j in range (1 , tr_len + 1 ): td_len = len (li.xpath('div[{0}]/table/tbody/tr[{1}]/td' .format (i,j))) for k in range (1 , td_len + 1 ): small_category = li.xpath('div[{0}]/table/tbody/tr[{1}]/td[{2}]/a/text()' .format (i,j,k))[0 ].strip() small_category_num = li.xpath('div[{0}]/table/tbody/tr[{1}]/td[{2}]/b/text()' .format (i,j,k))[0 ].strip().replace("(" ,"" ).replace(")" ,"" ) small_categories.append(small_category) small_categories_num.append(int (small_category_num)) return (big_categories,small_categories,small_categories_num)
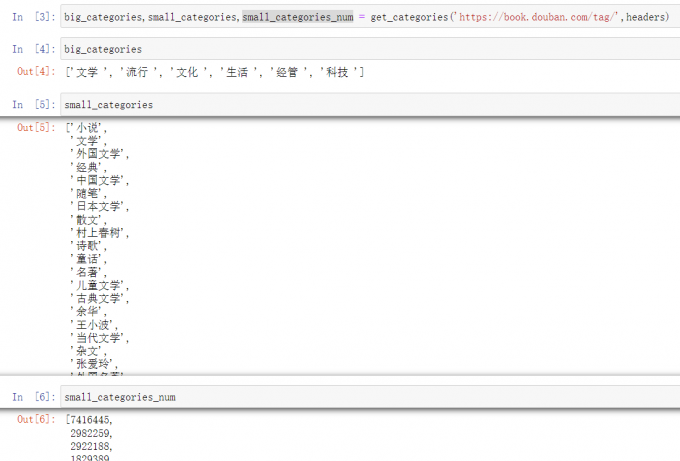
1 big_categories,small_categories,small_categories_num = get_categories('https://book.douban.com/tag/' ,headers)
结果如下
4 爬取对应书籍
观察发现每个类别的网站名称为:
https://book.douban.com/tag/XX?start=JJ&type=T
其中的XX代表标签的中文,JJ代表20的整数倍。也就是每一页一共20本书。
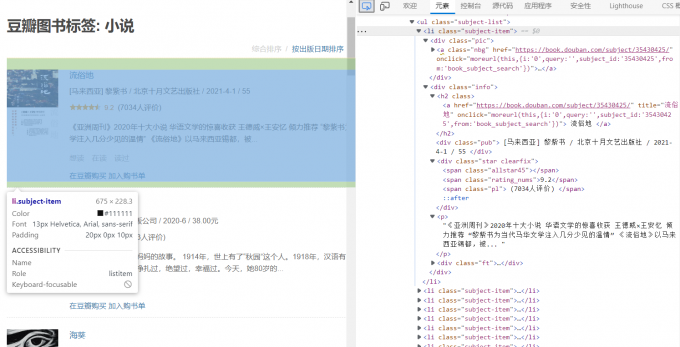
我们以”流俗地“这本书为例子,仔细观察右侧的元素表:
其中,图片链接在 div class = 'pic '中 文字信息在 div class = 'info ’ 中。
对各个数据进行爬取。包含数据及注意事项如下:
img_id: 图片的地址。藏在img的src属性下。
book_id: 图书id
book_address: 图书的豆瓣详情链接
star_score: 评分数。注意有些图书因为图书评分人数过少,而不显示评分。
star_nums: 评分人数:我们应该要找到对应的人数,需要对字符串做处理。
author_country: 根据豆瓣显示,国籍基本在[]和【】这两个框里,可以使用字符串处理,不过有非常多的特殊情况。而且外国书籍还会出现翻译者。
tranlator_name :翻译者
book_press : 出版社
book_time: 出版时间
book_money: 书的价格。由于有美元日元等等一系列,所以判定比较复杂,直接导入字符串吧。
book_abstraction:书的摘要。
重点!!!!
以上的数据部分都可能会出现并不存在于HTML结构中,再循环爬取的途中,可能会因为不存在而产生报错。
最好使用
这一方法来”逃避“错误。
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 def find_book (headers ,small_categories, small_categories_num ): bookdatas = pd.DataFrame(columns=['book_id' ,'book_type' ,'book_name' ,'book_address' ,'img_id' ,'star_score' ,'star_nums' ,'author_country' ,'author_name' ,'translator_name' ,'book_press' ,'book_time' ,'book_money' ,'book_abstraction' ]) new_num = [] for i in small_categories_num: new_num.append(int (100 )) no = 0 for i in small_categories: no = 0 book_type = i for j in range (0 ,new_num[no],20 ): print ('{0} {1}' .format (i,j)) try : url = 'https://book.douban.com/tag/{0}?start={1}&type=T' .format (i,j) res = requests.get(url,headers=headers) html = res.text xp = etree.HTML(html) li = xp.xpath('/html/body/div[3]/div[1]/div/div[1]/div/ul' ) for k in range (1 ,21 ): img_id = '' book_id = '' book_address = '' book_name = '' star_score = 0 star_nums = '' author_country = '' author_name = '' translator_name = '' book_press = '' book_time = '' book_money = '' book_abstraction = '' img_id = li[0 ].xpath('li[{0}]/div[1]/a/img/@src' .format (k))[0 ].strip() book_id = li[0 ].xpath('li[{0}]/div[1]/a/@href' .format (k))[0 ].strip().split('/' )[-2 ] book_address = li[0 ].xpath('li[{0}]/div[1]/a/@href' .format (k))[0 ].strip() book_name = li[0 ].xpath('li[{0}]/div[2]/h2/a/text()' .format (k))[0 ].strip() if li[0 ].xpath('li[{0}]/div[2]/div[2]/span[2]/text()' .format (k)): star_score = li[0 ].xpath('li[{0}]/div[2]/div[2]/span[2]/text()' .format (k))[0 ].strip() star_score = float (star_score) else : star_score = float (6.0 ) try : star_nums = li[0 ].xpath('li[{0}]/div[2]/div[2]/span[3]/text()' .format (k))[0 ].strip().split('人' )[0 ].replace('(' ,'' ).replace('少于' ,'' ) print (star_nums) except : star_nums = '0' print (star_nums) star_nums = int (star_nums) olddata = li[0 ].xpath('li[{0}]/div[2]/div[1]/text()' .format (k))[0 ].strip().replace(' ' ,'' ) newdata = olddata.split('/' ) if len (newdata) == 4 : author_country = '中' author_name = newdata[0 ] translator_name = author_name book_press = newdata[1 ] book_time = newdata[2 ] book_money = newdata[3 ].split('.' )[0 ] if len (newdata) == 5 : if newdata[0 ].find(']' ) != -1 : author_country = newdata[0 ].split(']' )[0 ].split('[' )[1 ] author_name = newdata[0 ].split(']' )[1 ] elif newdata[0 ].find('】' ) != -1 : author_country = newdata[0 ].split('】' )[0 ].split('【' )[1 ] author_name = newdata[0 ].split('】' )[1 ] else : author_name = newdata[0 ] translator_name = newdata[1 ] book_press = newdata[2 ] book_time = newdata[3 ] book_money = newdata[4 ].split('.' )[0 ] try : book_abstraction = li[0 ].xpath('li[{0}]/div[2]/p/text()' .format (k))[0 ].strip() except : book_abstraction = '暂无摘要' print (book_name) bookdata_1 = [book_id,book_type,book_name, book_address,img_id,star_score,star_nums,author_country,author_name,translator_name,book_press,book_time,book_money,book_abstraction] bookdata_1 = pd.DataFrame([bookdata_1],columns=['book_id' ,'book_type' ,'book_name' ,'book_address' ,'img_id' ,'star_score' ,'star_nums' ,'author_country' ,'author_name' ,'translator_name' ,'book_press' ,'book_time' ,'book_money' ,'book_abstraction' ]) bookdatas = bookdatas.append(bookdata_1) time.sleep(0.05 ) except : break no = no + 1 return bookdatas
1 book_datas = find_book(headers ,small_categories, small_categories_num)
得到数据需要大概25分钟。
5 数据处理和保存
1 2 book_datas.to_excel('bookdatas.xlsx' ,index = False ) book_datas.to_csv('bookdatas.csv' ,index = False )
由于爬取时意外性很强,可以使用to_excel 导出至excel文件里,这样可以在excel里观察数据。
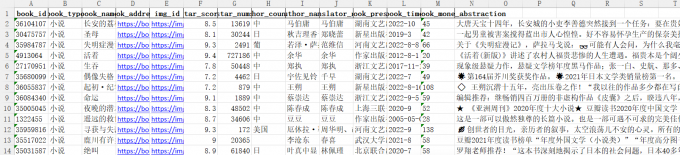
excel观察发现,还是存在大量,空白值和重复值,以及特殊值。
也可以使用book_datas.info() 和book_datas.head(10)这些命令来观察。
不过我们已经超量爬取了数据,可以直接把这些数据去除。这是最懒最省事的方法hhhh。
而且book_time出现一些错位数据,管他的,直接删掉吧,反正出版时间在未来数据库中也没啥用。
1 2 3 4 5 6 7 8 book_datas = pd.read_csv('bookdatas.csv' ) del (book_datas['book_time' ])book_datas.info() book_datas_1 = book_datas .drop_duplicates(subset=['book_id' ], keep='first' ) book_datas_2 = book_datas_1.dropna(axis=0 , how='any' ) book_datas_2.to_csv('book_data_2.csv' ) book_datas_2.to_excel('book_data_2.xlsx' )
book_datas_2就是我们最终的数据。