# 路径操作 import os # 文件操作 import shutil # torch相关 import torch import torch.nn as nn import torchvision from torchvision import transforms from torch.autograd import Variable # 日志 import logging import random import numpy as np import matplotlib.pyplot as plt # 绘图展示工具 # 计算机视觉cv2 import cv2 import math # 图像处理 from PIL import Image, ImageEnhance
观察图片结构
1 2 3 4 5 6 7 8
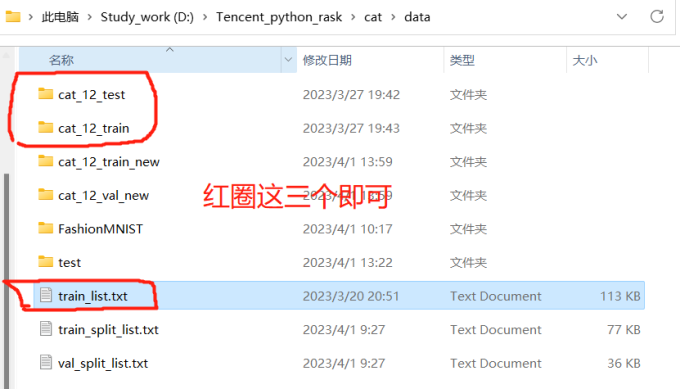
# 使用Python的Pillow库来获取图片的大小信息, folder_path = 'data/cat_12_train'# 文件夹路径 for file_name in os.listdir(folder_path): if file_name.endswith('.jpg'): file_path = os.path.join(folder_path, file_name) with Image.open(file_path) as img: width, height = img.size print(f'{file_name}: {width} x {height} pixels')
预期结果:
1 2 3 4 5
02WsuJX3pImwcyEKjFvkQqDSAaV8HoG5.jpg: 333 x 500 pixels 03j9aZ5Gkq7vMDRnVQFwfbrHx8TEeoch.jpg: 500 x 402 pixels 04Iv3QNKtu2DAfRTgs9XZwBMb1Cm7l6P.jpg: 500 x 327 pixels 07FlA9MgYrTXDSaoQZuOzf6NWLyI3mR4.jpg: 200 x 200 pixels ......
## 统计训练集各类猫的数目,防止样本不平衡问题。 import matplotlib.pyplot as plt import pandas as pd
withopen("data/train_list.txt", "r") as f: labels = f.readlines() labels = [int(i.split()[-1]) for i in labels]
counts = pd.Series(labels).value_counts().sort_index().to_list() names = [str(i) for i inlist(range(12))] data = list(zip(counts, names)) source = [list(i) for i in data] source # 每个都是180个数据,不存在样本不平衡问题 ''' [[180, '0'], [180, '1'], [180, '2'], [180, '3'], [180, '4'], [180, '5'], [180, '6'], [180, '7'], [180, '8'], [180, '9'], [180, '10'], [180, '11']] '''
数据集的构建
1 2 3 4 5 6 7
# 导包 import torchvision.transforms as transforms from torchvision.datasets import ImageFolder from torch.utils.data import DataLoader import matplotlib.pyplot as plt import random import os
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# pytorch的手册及源码有讲解。 torchvision.datasets.ImageFolder()要求根目录下建立分类标签子文件夹,每个子文件夹下归档对应标签的图片,因此需要给每个标签建立文件夹,并且遍历样本,将每个样本复制到对应的文件夹中。 """A generic data loader where the images are arranged in this way by default: ::
root/cat/123.png root/cat/nsdf3.png root/cat/[...]/asd932_.png This class inherits from :class:`~torchvision.datasets.DatasetFolder` so the same methods can be overridden to customize the dataset."""