12猫分类学习笔记四(优化+知识篇)
12猫分类学习笔记四(优化+知识篇)
附加指标
模型参数:25,557,032
FLOPs: 3.51G 。
引用论文:Deep Residual Learning for Image Recognition 2015
该论文由何凯明(Kaiming He)、张学工(Xiangyu Zhang)、Ren Shaoqing 以及 Sun Jian 等人撰写。论文中提出了残差学习的概念,将残差块(Residual Block)引入到深度神经网络中,通过其解决了深度神经网络训练中出现的梯度消失和梯度爆炸等问题。同时,通过使用深度残差网络,ResNet 在2015年 ImageNet 图像分类竞赛中夺得冠军,成为了当时最先进的图像分类模型。
优化方向
- 在接下来的工作中,可以考虑增加图像增强操作,例如图像裁剪,图像亮度调整,图像对比度调整等待,从而丰富训练集,防止过拟合。
- 可以考虑使用其他残差网络,例如ResNet101,ResNet152进行改进。或者对Resnet的网络进行调参,进一步细化。
- 可以从超参数的角度进一步优化,比如调整学习率,自适应学习率策略,训练轮数等。
- 还没有使用过不同的优化器,只是使用了较强的Adam。

思考问题
Q1:dropout与残差网络的差别
Dropout 和残差网络(ResNet)是深度神经网络中两个独立的概念,它们的作用和效果也不完全相同。下面是它们的区别和相同点:
区别:
- 作用不同:Dropout主要可以用于提高神经网络的泛化能力,防止过拟合。而残差网络主要用于解决深度神经网络的退化问题和提高网络效果。
- 使用位置不同:Dropout 层通常在深层网络中加入,而残差连接则是在不同层之间引入。
相同点:
- 都可以用于提高深度神经网络的性能和泛化能力。
- 都是对深度神经网络进行正则化的一种方式。
- 在深度神经网络训练时,都可以缓解过拟合的问题。
需要特别注意的是,在训练深度神经网络时,应保持谨慎,在合适的时间和地点使用 dropout 和残差连接,以避免过拟合和过度复杂化。
Q2: 什么样的数据集适合残差神经网络?
残差神经网络(ResNet)是一种非常强大的深度学习模型,适用于大多数图像分类、目标检测、分割等任务。但是,并不是所有的数据集都适合使用 ResNet,下面是一些数据集适合使用 ResNet 的特点:
- 复杂数据集:ResNet由于具有深度网络等结构,使得它具有很强的特征表达能力,适合处理复杂的图片数据集,比如CIFAR-10、CIFAR-100、ImageNet等数据集。
- 大规模数据集:ResNet是一种深度卷积神经网络,需要大量的样本数据来训练,才能避免过拟合的问题。因此,ResNet适用于大规模图像数据集,这些数据集包含了大量的样本信息,如ImageNet等。
- 需要解决梯度消失问题的数据集:ResNet提出了残差模块,使得模型能够更好地训练,避免了梯度消失的问题,因此适用于需要解决梯度消失问题的复杂数据集。
综上所述,ResNet适合处理大规模、复杂的图片数据集,其中需要解决梯度消失问题的数据集更加适合使用 ResNet。除此之外,如果其它模型在处理该数据集时表现不佳或出现了梯度消失、梯度爆炸等问题,可以考虑使用 ResNet 进行尝试。
Q3: 对于猫的分类这类单一物种分类的数据集,使用什么样的神经网络比较好?
针对猫的分类这类单一物种分类的数据集,可以考虑使用如下两种神经网络:
- 浅层神经网络:对于图片数量不多或者图片较为简单的数据集,浅层神经网络可能会表现得更好。浅层神经网络具有较少的层数和参数,训练速度较快,对于简单的数据集可能在分类效果上仍旧不错。
- 迁移学习的卷积神经网络:通常卷积神经网络在图像分类问题上表现非常好,使用迁移学习技术,可以将预训练好的模型权重复用在猫的分类这个任务上,让模型更快速地收敛,提升训练效果。常见的预训练模型包括VGG、ResNet、Inception等。
- 卷积神经网络(CNN):CNN是深度学习中最常用的一种神经网络,它可以自动学习图像中的特征,从而实现对图像分类任务。对于猫的分类这类相似的数据集,使用卷积神经网络是比较常见的选择。
- 残差神经网络(ResNet):ResNet在CNN的基础上提出了残差连接与深度残差网络,在语音识别等领域已经证明该模型效果出色。ResNet模型可以直接从低深度模型训练到更深的模型阶段,更能够有效地提升模型性能,适用于相似的数据集分类任务。
此外,还有其他一些网络模型,比如AlexNet等,在图像分类任务上也有很好的表现,可以酌情选择。综合考虑模型的准确率、复杂度、训练速度等因素,可以选择一个最合适的模型来处理猫的分类这类单一物种分类的数据集。同时,可以对数据集进行必要的增强技术,如数据增强,来改善模型的性能和泛化能力。
Q3:如何证明自己的数据增强方法是合适的,较优的?
以下是几个证明自己数据增强方法合适、较优的方法:
- 分割分析法:将数据分为训练集与测试集两部分,统计经过数据增强方法的训练集上的准确率、F-score等指标情况,并与未经过数据增强处理的训练集进行比较,如果经过增强处理的数据集表现更优,则说明数据增强方法较优。
- 决策曲线分析法:该方法基于Vallecula曲线,通过使用经过数据增强处理的数据集、未经过数据增强处理的数据集和干净数据集训练模型,并对模型进行测试,绘制出曲线图,较优的数据增强方法在曲线上的面积应最大。
- T-SNE可视化方法:使用T-SNE降维算法将数据集数据可视化,观察不同类别数据点是否在不同的区域内,在不同区域内重叠情况如何,及不同类别之间的距离是否越来越远,如果经过数据增强处理的数据集表现更优,则说明数据增强方法较优。
- 对比实验法:通过选用多种不同的数据增强方法,将训练数据集分别经过这些方法的增强处理,并对模型进行测试,找到正确率更高的数据增强方法。
需要注意的是,数据增强方法的优劣与任务有很大关系,直接使用一种数据增强方法在所有任务中都表现良好是不可能的。最好的方法是根据具体任务和数据特点,选择或尝试多种数据增强方法进行测试,以找到最适合的数据增强方法,并证明其优劣。
Q4:为什么选择了pytorch,而不是paddle?它们差异在哪?
以下是PyTorch和Paddle的优缺点及不同点:
PyTorch的优点:
- 易于使用和学习:PyTorch的API简单、灵活,具有清晰的文档和较少的代码。它的API很容易理解和学习,因此在深度学习社区中拥有大量的支持者和开发者。
- 动态图机制:PyTorch使用动态计算图机制,能够更加灵活地构建、改变和调试模型结构,使用起来非常方便。
- 建模速度快:PyTorch的灵活性和简单的API极大地提高了建模速度,软件设计和开发人员可以快速构建复杂的神经网络。
- 大型模型训练:能够轻松地训练深度神经网络模型,能够轻松地处理大型模型训练以及从海量数据中学习。
Paddle的优点:
- 高性能的分布式训练:Paddle可以在大规模分布式集群上运行,提供高效的模型并行和数据并行算法,因此它非常适合大规模数据和复杂的模型。
- 动态图和静态图:Paddle不像PyTorch只使用动态图。Paddle同时支持静态图和动态图优势。用户可以根据需要选择任何功能。
- 与硬件的高度优化:Paddle是为深度学习和高性能计算而生的。它通过与自主研发的AI芯片和配套的软件生态系统紧密集成,以便更好地满足业界的需求。
PyTorch和Paddle的不同点:
- 计算图:Pytorch的计算图是动态图,很适合在迭代式环境中工作,在开发过程中具有更大的灵活性。Paddle的计算图是静态的,很适合在实时系统和大型开发中使用。
- 硬件支持:Paddle具有更强的硬件支持,可以很好地与NVIDIA的一些GPU卡片和自主研发的AI芯片等硬件环境相集成。PyTorch支持广泛,但在硬件上没有这样先进的支持。
- 教育支持:PyTorch的吸引力和使用方法非常适合教育用途,Paddle更适合于科研和工业应用。
总体而言,PyTorch更适合用于小规模和中等规模的实验和研究,并适合初学者快速上手。而Paddle更适合于大型工业应用或需要高效处理分布式训练的科研团队。
Resnet网络详细解释
强烈建议去看原论文,很好懂而且对比实验数据很详细。Deep Residual Learning for Image Recognition
本项目使用典型的图片分类网络ResNet50,ResNet是2015年提出的结合残差模块的更深层神经网络,在图像分类问题上达到很好的效果。
ResNet50有两个基本的块,分别是Conv Block和Identity Block:
- Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;
- Identity Block输入维度和输出维度相同,可以串联,用于加深网络的。
什么是残差网络?
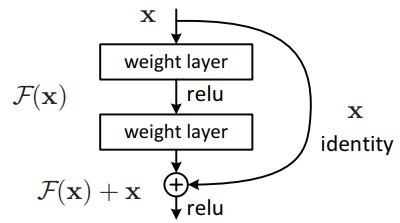
神经网络可以视为一个非线性的拟合函数,由x映射为H(x)。那么假如我的网络输出不是H(x),而是H(x)- x,记为F(x),即为残差网络,网络的输出为输出与输入的残差。那么新的网络设计对网络有什么改变呢?
假设一个模型所需的层次比较浅,如果用一个较深层次的模型实现这个模型,可以认为在浅层次网络的基础上添加了许多层恒等映射,即H(x) = x,对于残差网络而言,即为F(x) = 0。训练一个输出为零的映射要比训练一个恒等映射难得多,因此可以认为这样的网络应该对于深层次的神经网络构造有所帮助。当然实际情况会比恒等映射复杂,但是我们有理由认为深层次网络是在恒等映射附近范围浮动。引入残差网络我们就不是把恒等映射当成一个要去学习的函数了,而是将恒等映射作为预处理在基础上进行微小的浮动优化。原来我们要训练的是恒等映射与一小部分浮动,现在我们只需要训练一个零附近的映射,这应该会更加精确。
ResNet网络中的残差组件,其实就是将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。从而为了克服网络深度加深而产生的学习效率变低,以及随着网络加深,准确率下降的问题。残差组件如下图所示:
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
各个不同级别地Resnet层数表(截取自原论文):
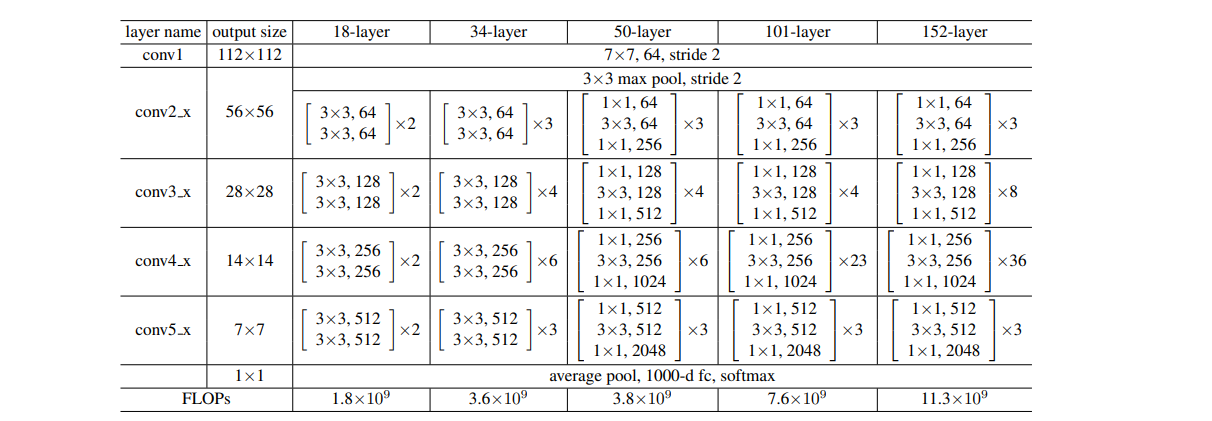
对于在ImageNet的数据中。我们可以看出网络神经越深,效果越好,这很有可能是因为残差网络的设计,导致了训练不至于过拟合。
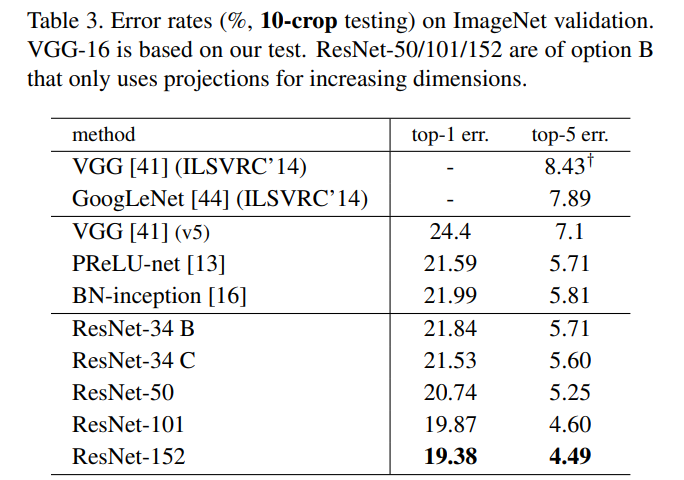
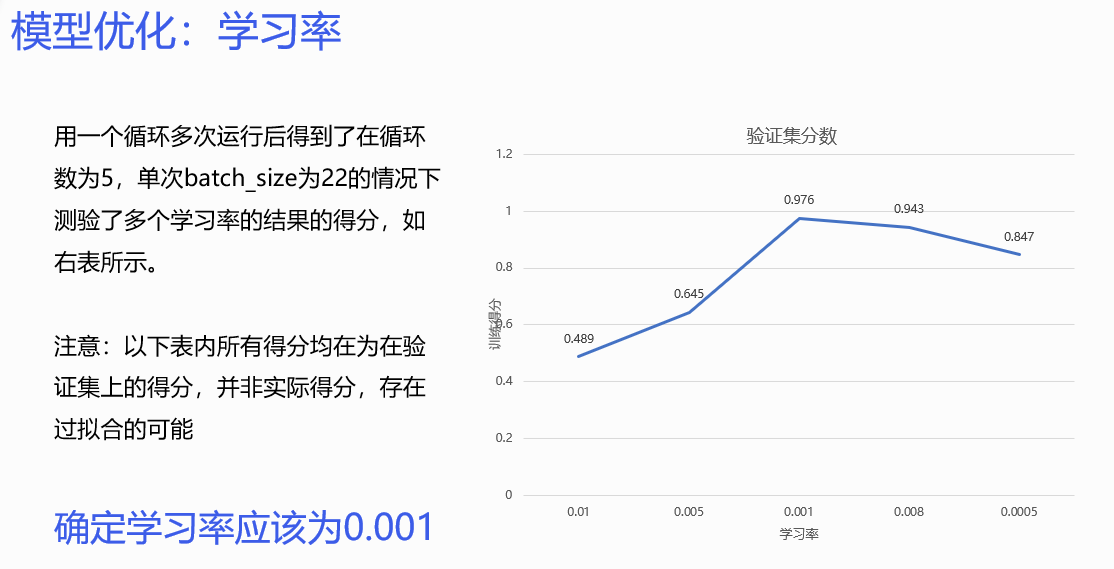
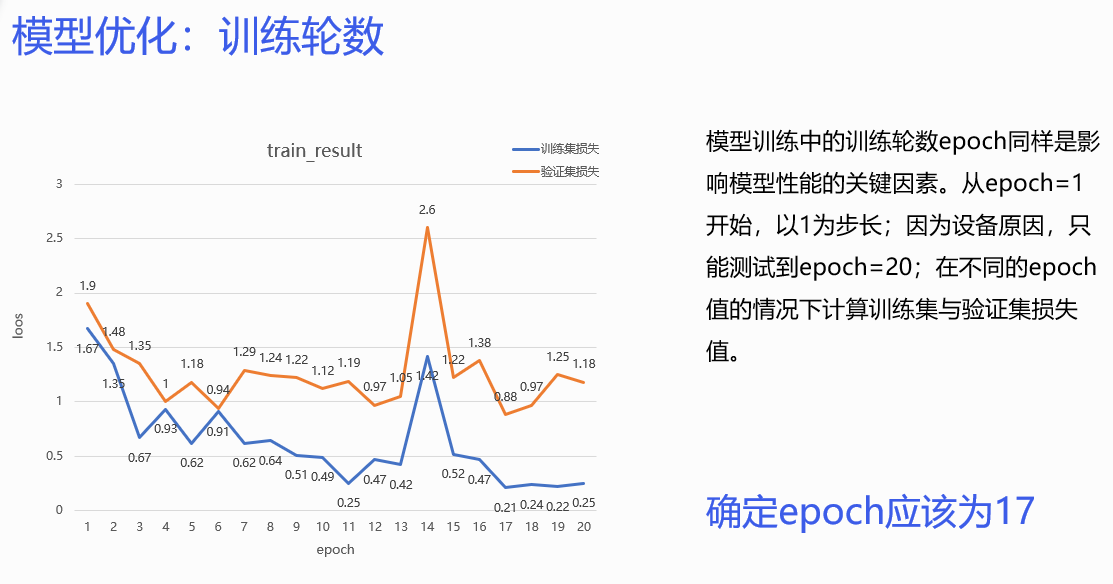
学习率,batchsize,epoch
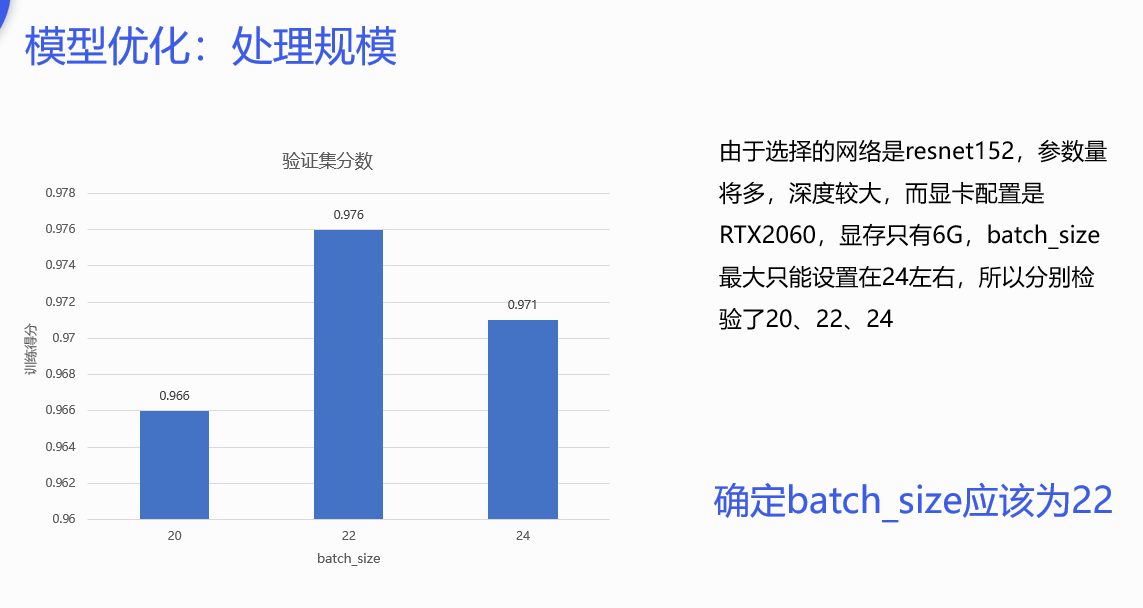
模型的创新之处:
- 借用了别人的数据集参数,改变了参数计算默认值,也就是因为Resnet是在ImageNet的训练集下,而不是我们的猫的训练集。
- 进行数据处理时,进行了样本平衡问题检验,观察出训练集所给样本,每种类别猫的数量相同,都为180,不需要进行额外处理。
计算模型参数
在PyTorch中,可以使用torchsummary来计算模型的参数量。torchsummary是一个辅助计算PyTorch模型参数量的库。
首先通过如下命令安装torchsummary:
1 | pip install torchsummary |
然后,通过以下代码即可计算模型的总参数量:
1 | import torch |
在上述代码中,需要将YourModel()替换为你自己的模型,(input_shape,)是模型输入的形状,可以是一个元组或列表。summary函数会打印出模型的结构和参数量信息。例如:
1 | ---------------------------------------------------------------- |
上面参数信息中的Total params即为模型的总参数量。
我这里input_size = (3,196,196) # 3为通道数
求FLOPS
在PyTorch中,可以使用thop (PyTorch-OpCounter)来计算模型的 FLOPs。thop 是一个轻量级但功能强大的库,可以计算模型的 FLOPs、参数量以及模型各个层的信息。
首先需要用如下命令安装 thop:
1 | pip install thop |
然后,在你的代码中,使用如下代码即可计算模型的 FLOPs:
1 | import torch |
其中,YourModel()需要替换为你自己的模型,batch_size、in_channels、input_size是输入数据的维度,flops为计算得到的 FLOPs 量,params 是参数。