

深度图Depth_Map
深度图(Depth Map)
深度图是什么
深度图(depth map)是一种灰度图像,其中每个像素点距离相机的距离信息。它是计算机视觉中常用的一种图像表示方式,用于描述场景的三维结构。
深度图的获取方式
深度图的发展历史可以追溯到20世纪60年代。最初,深度图像是通过手工标注或利用先验知识推测出来的。随着计算机视觉技术的发展,深度图像的获取方法和算法也不断进步和完善。
深度图的获取方式有多种,常见的方法包括:
通过激光雷达或结构光等传感器获取深度信息,再将其转换为深度图像。
利用双目或多目相机的视差信息计算深度,再将其转换为深度图像。
利用先验知识或模型对图像进行分析,推测出每个像素点的深度信息。
激光雷达或结构光等传感器的方法
激光雷达或结构光等传感器获得的深度,可以得到绝对深度,因为他们的数据是测出来的,根据TOF计算得到的真实距离。所以在连续的图片序列中,由于深度是绝对的,他们具有一样的参考价值。
激光雷达
这种方法也被叫做TOF方法(Time Of Fly)即通过激光/雷达波发出和收到的时间差,结合光速,计算信号在这段时间所走过的路程,所以也就能获得不同物体距离激光发射 ...

三维空间的表示方法
三维空间的表示方法
http://t.csdnimg.cn/PauoT
显示表示
体素Voxel,点云Point Cloud,三角面片Mesh等。
隐式表达
符号距离函数Signed Distance Funciton(SDF),占用场Occupancy Field,神经辐射场Neural Radiance Field(NeRF),TSDF截断符号距离。TSDF截断符号距离 | CJH’s blog (cjh0220.github.io)
函数function与场field
先回顾一下函数和场的概念,我认为函数和场实际上都是代表了一种映射关系。
函数 f(x)=y 是自变量 x 的集合到因变量 y 集合的映射,也就是每个x对应一个y。
场的定义是向量到向量或数的映射,空间中的场可以认为是 “空间中点”到“点的属性”的映射,也就是每个点对应这个点的属性。以磁场为例,磁场就是空间中每个点都具有一个磁感应矢量B,也就是点到向量的映射,即空间中每个点都对应到一个特定的向量B。在其他情况下,点不一定对应到向量,也可以对应到标量或者其他属性,只要是空间中点到属性的映射都是空间场。( 一般用坐标 ...

铰链损失Hinge_Loss
铰链损失Hinge Loss
铰链损失(Hinge Loss)是一种常用于 支持向量机(SVM) 中的损失函数,尤其是在分类任务中。它衡量模型的预测结果与实际标签之间的差异,并试图最大化分类的间隔,使样本尽量远离决策边界。
铰链损失的公式
假设模型的输入为特征向量 x,目标标签为 y(取值为 +1 或 −1),模型的预测为 y^=wTx+b\hat{y} = w^T x + by^=wTx+b。铰链损失的公式如下:
Hinge Loss=max(0,1−y⋅y^)\text{Hinge Loss} = \max(0, 1 - y \cdot \hat{y})Hinge Loss=max(0,1−y⋅y^)
公式解释
y 是真实标签,取值为 +1 或 −1。
y^\hat{y}y^ 是模型预测的值。
当y⋅y^≥1y \cdot \hat{y} \geq 1y⋅y^≥1 时,损失为 0,这意味着样本被正确分类,并且与决策边界的间隔足够大。
当 y⋅y^<1y \cdot \hat{y} < 1y⋅y^<1 时,损失为1−y⋅y^1 - y \cdot \h ...

三维重建学习(八)SLAM
三维重建学习(八)SLAM
图像的词袋表示,图像检索
给一张图片,转化为词频向量。相似的图像就是某个小图像比较高。也能分类。难在如何生成词典。
词典来自于特征提取与表示
把所有特征做成描述符,再做聚类。
给一个块,看跟那个块近,就认为他是哪个单词。将所有小区块变成了索引值。每个框框统计,就得到词袋描述。
相似性度量
给两个图像向量,进行相似性度量,算余弦距离即可。
TF-IDE 词频因子
对他进行改良,对向量进行加权,凸显了部分单词的重要性和抑制了部分单词。
倒排索引加速运算。重要性大的先比较。
捆绑调整
摄像机的内参数不优化。
生成树
SLAM介绍
扫地机器人的初始化步骤,就是走边房间进行建图与定位。绿色的是摄像机,黑色为点云。
传感器分类
传感器可分为俩个类:
携带于机器人本体上的,例如机器人的轮式编码器、相机、激光等等。
安装于环境中的,例如前面讲的导轨、二维码标志等等。
摄像机:单目、双目、深度相机。
SLAM开源方案
ORB-SLAM
核心就是三个线程:
跟踪:确定当前帧位姿
建图:完成局部地图构建
回环修正:回环检测以及基于回环信息修正 ...

论文精读(八)OReX:使用神经场从平面横截面重建物体
论文精读(八)OReX:使用神经场从平面横截面重建物体
原论文
代码与数据: https://github.com/haimsaw/OReX
引言
从平面横截面重建3D形状是一项挑战,受到医学成像和地理信息学等下游应用的启发。输入是一个在空间中稀疏的平面集合上完全定义的输入/输出指示函数,输出是指示函数到整个体积的插值。以前的工作解决这个稀疏和不适定的问题,要么产生低质量的结果,或依赖于额外的先验,如目标拓扑结构,外观信息,或输入法线方向。在本文中,我们提出了OReX,这是一种仅根据切片进行3D形状重建的方法,其特征是将神经场作为插值先验。在输入平面上训练一个适度的神经网络,以返回给定3D坐标的内部/外部估计,从而产生一个强大的先验知识,从而产生平滑性和自相似性。这种方法的主要挑战是高频细节,因为神经先验过于平滑。为了缓解这一问题,我们提供了一个迭代估计架构和一个分层输入采样方案,鼓励从粗到精的训练,使训练过程在后期阶段专注于高频。此外,我们确定和分析了波纹状的效果源于网格提取步骤。我们通过在网络训练期间围绕输入/输出边界正则化指示函数的空间梯度来缓解它,从根本上解决问题。通过大量的定 ...

三维重建学习(七)SFM
三维重建学习(七)运动恢复结构(SfM)系统解析
回顾
单应矩阵
单应矩阵–空间平面在两个摄像机下的投影几何。
捆绑调整BA(Bundle Adjustment)
恢复结构和运动的非线性方法。
P3P求解摄像机位姿
核心思路:
求解A,B,C三点在当前摄像机坐标系上的坐标;
通过A,B,C在当前摄像机下的坐标以及其在世界坐标系下的坐标,估计摄像机相对于世界坐标系的旋转与平移。
SfM系统
输入输出
输入:多张图片
输出:3D点云(structure),摄像机位姿(motion)
问题描述
已知:三维场景的m张图像以及每张图像对应的摄像机内参数矩阵Ki(i=1,...,m)K_i(i=1,...,m)Ki(i=1,...,m)
求解:
三维场景结构,即三维场景点坐标Xj(j=1,...,n)X_j(j=1,...,n)Xj(j=1,...,n);
m个摄像机的外参数RiR_iRi及Ti(i=1,...,m)T_i(i=1,...,m)Ti(i=1,...,m)
特征提取SIFT
相当于为每个像素提取一个梯度方向,并累加。所有梯度方向做累加,看最大的方向 ...

三维重建学习(一~六)传统视觉几何
三维重建学习(一)摄像机几何
计算机视觉之三维重建(1)—摄像机几何_摄像机像平面-CSDN博客
【2022B站最好最全的【三维重建】课程!!!北邮教授竟然把三维重建讲的如此通俗易懂,学不会UPZHIJIE 退网下架!!!-人工智能/计算机视觉/三维重建】https://www.bilibili.com/video/BV1DP41157dB?p=4&vd_source=bd967f0d540a64617b8b612bc0f0f9a3
针孔摄像机
基本上就是初中学习的小孔成像的原理。注意,我们平常所说的照片直接就是“虚拟像平面”,不用正负号。
小孔成像模型,运用了相似三角形原理。k方向也就是常说的z方向,深度方向。下面这张图演示了从jok面上做的二维映射。
加了透镜提高亮度,还是相似三角形原理。
物体聚焦有特定距离,如果实际物体过近,会导致失焦。
透镜还会产生畸变。
径向畸变:图像像素点以畸变中心为中心点,沿着径向产生的位置偏差,从而导致图像中的像发生形变。
枕形畸变
桶形畸变
拿不到连续的图片,只能拿到像素点。
坐标系变化需要修正,从摄像机坐标系-》像平面坐标系- ...
随机微分方程
随机微分方程
http://t.csdnimg.cn/SBEU0
随机微分方程(Stochastic Differential Equation, SDE)是一类包含随机过程的微分方程,用于描述系统在噪声或随机扰动影响下的动态行为。随机微分方程的形式通常可以表示为:
dXt=μ(Xt,t)dt+σ(Xt,t)dWtdX_t = \mu(X_t, t)dt + \sigma(X_t, t)dW_tdXt=μ(Xt,t)dt+σ(Xt,t)dWt
其中:
XtX_tXt 是随时间 ttt 变化的随机过程。
$\mu(X_t, t) $是漂移系数,决定了系统的确定性趋势。
σ(Xt,t)\sigma(X_t, t)σ(Xt,t)是扩散系数,控制了随机扰动的强度。
dWtdW_tdWt 是一个标准的维纳过程(Wiener process),也称为布朗运动,表示随机噪声。
随机微分方程在金融、物理、生物等领域中有广泛的应用。例如,布朗运动模型、金融市场中的股价模型(如Black-Scholes模型)等都可以通过随机微分方程来描述。解随机微分方程的主要方法包括伊藤积分和斯特拉托诺 ...

TSDF截断符号距离
TSDF:截断符号距离函数
http://t.csdnimg.cn/ZjYQq
如何从零学习基于 TSDF 的三维重建? - Merce的回答 - 知乎
https://www.zhihu.com/question/486921125/answer/2406613708
1 概念定义
截断符号距离函数(Truncated Signed Distance Function,简称TSDF)是一种用于表示三维空间中物体表面的数据结构。它将空间划分为一个规则的体素网格,并为每个体素存储一个有符号距离值。这个距离值表示该体素中心到物体表面的距离。在物体表面内部的体素具有负值,而在物体表面外部的体素具有正值。为了减少存储和计算的开销,TSDF通常会对距离值进行截断,即只存储距离物体表面一定范围内的体素的距离值。
2 TSDF用途:
三维重建:TSDF常用于从多视角的深度图像重建三维模型。通过将来自不同视角的深度信息融合到一个统一的TSDF表示中,可以生成一个完整且连续的三维模型。
表面提取:TSDF可以用于提取物体表面的三维网格模型。通过在TSDF中找到距离值为零的体素,可以得到物体表面的一个近 ...
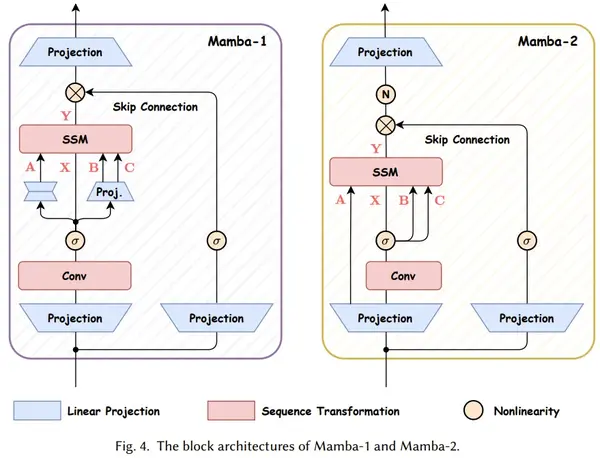
Mamba学习
Mamba学习
相关资源
[2312.00752] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arxiv.org)
state-spaces/mamba: Mamba SSM architecture (github.com)
非常简洁易读:[2408.01129] A Survey of Mamba (arxiv.org)
简介
在语言、音频、DNA序列模态上都实现SOTA,在最受关注的语言任务上,Mamba-3B超越同等规模的Transformer,与两倍大的Transformer匹敌,并且相关代码、预训练模型checkpoint都已开源
简言之,Mamba是一种状态空间模型(SSM),建立在更现代的适用于深度学习的结构化SSM (简称S6)基础上,与经典架构RNN有相似之处
Mamba = 有选择处理信息 + 硬件感知算法 + 更简单的SSM架构
与先前的研究相比,Mamba主要有三点创新:
对输入信息有选择性处理(Selection Mechanism)
硬件感知的算法(Hardware ...




