数据分析笔记1
数据分析笔记
企业数据分析方向
- 现状分析(分析当下数据):现阶段整体情况和各个部分构成占比
- 原因分析(分析过去数据):某一现状产生的原因,做出调整优化
- 预测分析(结合数据预测未来):结合已有数据预测未来发展趋势
原因分析:
离线分析(批处理)
面向过去,面向历史,分析已有数据:
在时间维度明显成批次性变化,1周1次/一天1次,又叫批处理。
现状分析
实时分析(流式处理)
面向当下,分析实时产生的数据。
所谓的实时是指从数据产生到数据分析到数据应用时间间隔很短,分秒毫秒级别。
预测分析
机器学习
基于历史数据和当下产生数据预测未来发生的事情。
侧重于数学算法的运用,如分类、聚类、关联、预测。
数据分析步骤
数据分析步骤重要性体现在:为开展数据分析提供了强有力的逻辑支撑。
步骤:
1、明确分析目的思路
2、数据收集
3、数据处理
4、数据分析
5、数据展现
6、报告撰写
1、明确分析目的和思路
- 目的是整个分析流程的起点,为数据收集处理分析提供清晰指引;
- 思路:使分析框架体系化,具有逻辑性,维度完整性,结果有效准确行;
- 需要数据分析方法论支持,如营销管理类理论。比如用户行为理论,PEST,5W2H分析法等。
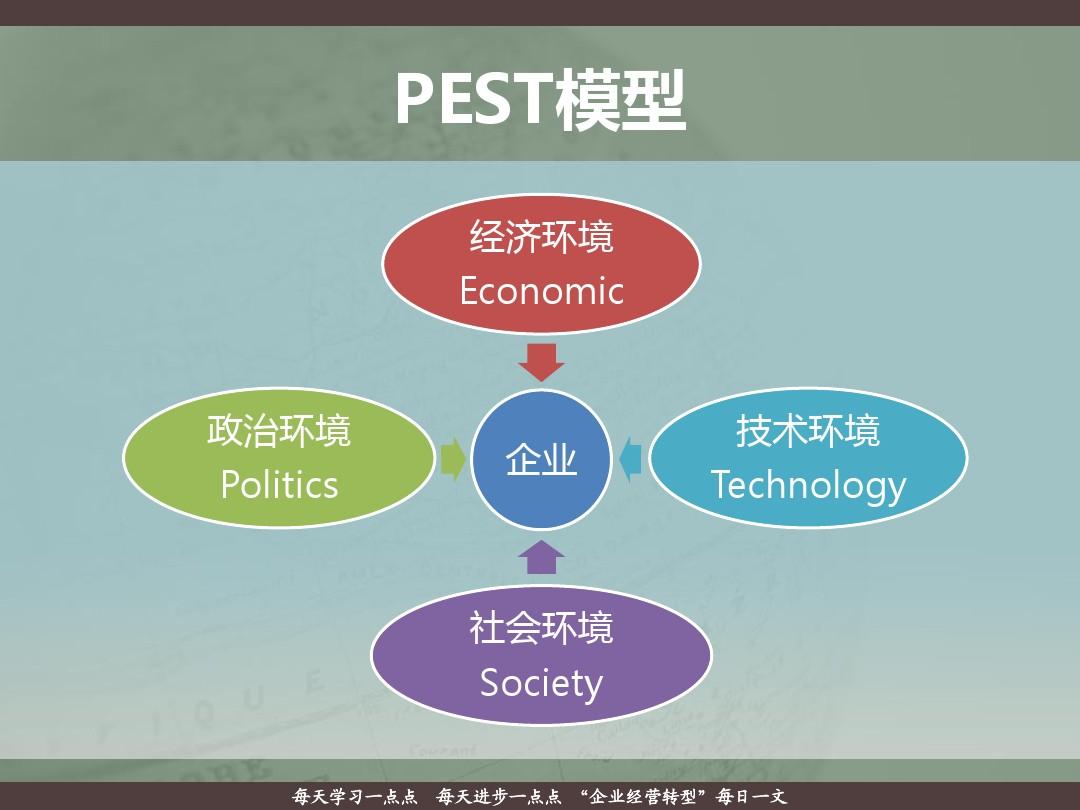
PEST分析法:
PEST分析是指宏观环境的分析,P是政治(politics),E是经济(economy),S是社会(society),T是技术(technology)。 在分析一个企业集团所处的背景的时候,通常是通过这四个因素来分析企业集团所面临的状况。
5W2H分析法:
发明者用五个以W开头的英语单词和两个以H开头的英语单词进行设问,发现解决问题的线索,寻找发明思路,进行设计构思,从而搞出新的发明项目,这就叫做5W2H法。
(1)WHAT——是什么?目的是什么?做什么工作?
(2)WHY——为什么要做?可不可以不做?有没有替代方案?
(3)WHO——谁?由谁来做?
(4)WHEN——何时?什么时间做?什么时机最适宜?
(5)WHERE——何处?在哪里做?
(6)HOW ——怎么做?如何提高效率?如何实施?方法是什么?
(7)HOW MUCH——多少?做到什么程度?数量如何?质量水平如何?费用产出如何?

2、数据收集
数据从无到有~数据传输搬运
- 业务数据
- 日志数据
- 爬虫数据
- 互联网公开数据
3、数据处理(数据预处理)
数据预处理需要对数据进行加工整理。主要包括:
- 数据清洗,数据转化,数据提取,数据计算;
目的:保证数据一致性和有效性,让数据变成干净规整的结构化数据。
4、数据分析
用适当的分析方法与工具,对处理过后的数据进行分析,提取有价值的细信息,形成有效结论的过程。
5、数据展示(数据可视化)
分析结果图表展示化。
6、报告撰写
分布式与集群
分布式:
多台机器,每台机器部署不同组件。
集群:
多台机器,每台机器部署相同组件
SSH协议
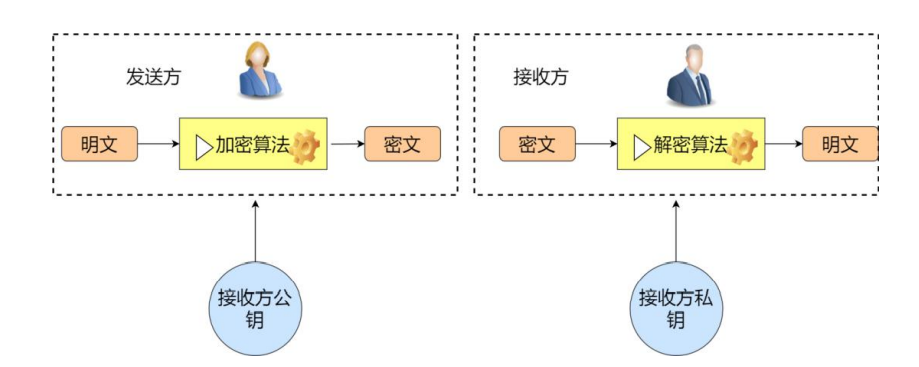
SSH为Secure Shell的缩写,是一种网络安全协议,专为远程登录会话和其他网络服务提供安全性的协议。
主要用途:用户加密实现远程登录,服务器之间的免密登录。
SSH协议中默认使用RSA算法实现非对称加密,需要2个密钥:公钥/私钥。
公钥与私钥是一对,如果用公钥对数据进行加密,只有用对应的私钥才能解密
Hadoop介绍
用java语言实现,开源
允许用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理。
Hadoop核心组件
- Hadoop HDFS(分布式文件存储系统):解决海量数据存储。
- Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
- Hadoop MapReduce(分布式计算框架):解决海量数据计算
Hadoop特性优点
扩容能力强
多台机器集群,可多可少灵活。
成本低
集群整体能力,集体廉价=廉价
效率高
分布式并行,并发数据
可靠性强
能自动维护数据的多份复制
Hadoop集群整体概述
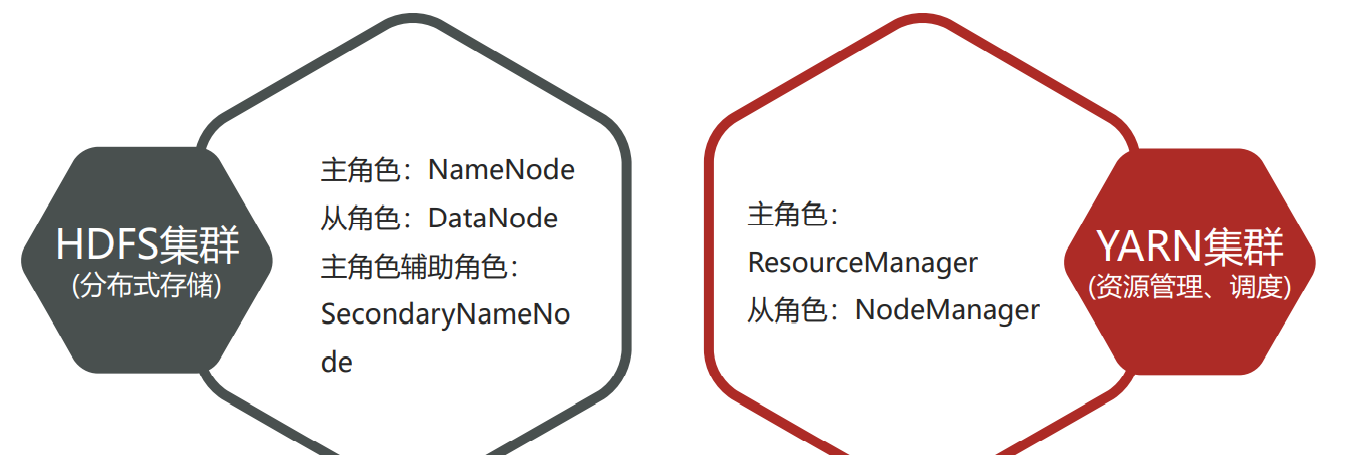
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 逻辑上分离,物理上在一起
- 两个集群都是标准的主从架构集群
分布式存储的优点
单机纵向扩展:磁盘不够加磁盘,有上限瓶颈限制
多机横向扩展:机器不够加机器,理论上无限扩展
分块存储好处
- 问题:文件过大导致单机存不下,上传下载效率低
- 解决:文件分块存储在不同机器,,针对块并行操作提高效率
切成块,
两个网站
副本机制的作用
冗余存储,保障数据安全
HDFS设计目标
- 硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每个组件都有可能故障。因此,故障检测和自动快速回复是HDFS的核心架构目标。
- HDFS上的应用主要是以流式读取数据。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的高吞吐量。
- 典型的HDFS文件大小是GB到TB的级别。所以HDFS被调整成 支持大文件。他应该提高很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中应该支持千万级别的文件。
MapReduce思想
- Map表示第一阶段,负责拆分:即把复杂的任务分解为若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小人物可以并行计算,彼此间几乎没有依赖关系。
- Reduce表示第二阶段,负责“合并”:即对map阶段的结果进行全局汇总。
- MapReduce借鉴了 函数式语言中的思想,用MaP和Reduce两个函数提供了高层的并行编程抽象模型。
- map:对一组数据元素进行某种重复式的处理。
- reduce:对Map的中间结果进行某种进一步的结果整理。
MapReduce实例进程
三类
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
数据类型
- kv键值对。
阶段组成:
一个Map一个Reduce,只能串行运行
Map阶段执行过程
第一阶段:逻辑切片
第二阶段:按行读取数据
第三阶段:map方法处理数据
第四阶段:分区
第五阶段:写入内存缓冲区,溢出的时候根据key进行排序
第六阶段:合并
Reduce阶段执行过程
- 第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
- 第二阶段:把拉去来的数据,全部进行 合并merge,把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对传入到HDFS文件中。
shuffle概念
- Shuffle的本意是洗牌,混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
- 而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是 将map端的无规则输出按指定的规则打乱成具有一定规则的数据,以便reduce端接受处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
YARN3大组件
- ResourceManager(RM)
YARN集群中的主角色,决定系统中所用应用程序之间的资源分配的最终权限,及6最终仲裁者。
接受用户的作业提交,并通过NM分配,管理各个机器上的计算资源。
- NodeManager (NM)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。
根据RM命令,启动Container容器、监视容器的资源使用情况。并向RM主角是汇报资源使用情况。
- ApplicationMaster (AM)
用户提交的每个应用程序均包含一个AM。
应用程序内的“老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
调度器策略
- 三种调度器
FIFO Schedeler(先进先出调度器),默认的Capacity Scheduler(容量调度器),Fair Scheduler(公平调度器)
什么是Hive
- Apache Hive是一款建立再Hadoop之上的开源数据仓库系统,可以将Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,成为HQL(hive查询语言)。
- 核心:将HQL转化为MapReduce程序
- Hive利用HDFS存储数据,利用MapReduce查询分析数据