阶段性文章总结
阶段性总结
整理医学超声图像处理、3D Gaussian Splatting(3DGS)及大语言模型(LLM)相关文献,按发表时间排序,供后续研究参考。
目录
1 医学超声图像处理
本节按时间顺序梳理超声图像/视频分割、分类与智能分析的代表性工作,从经典 U-Net 到基础模型 SAM 及最新综述。
1.1 U-Net(2015)
| 字段 | 内容 |
|---|---|
| 文章名称 | U-Net: Convolutional Networks for Biomedical Image Segmentation |
| 作者与机构 | Olaf Ronneberger, Philipp Fischer, Thomas Brox;德国弗莱堡大学(University of Freiburg) |
| 发布时间 | 2015 年 5 月(MICCAI 2015) |
| 发布地址 | https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ |
| 论文地址 | https://arxiv.org/abs/1505.04597 |
| GitHub 地址 | https://github.com/milesial/Pytorch-UNet(社区广泛使用的 PyTorch 复现;原文无官方仓库) |
主要工作与挑战
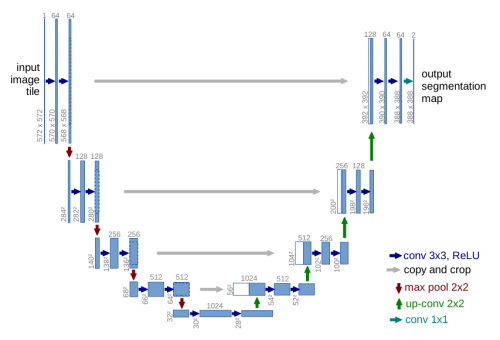
- 提出对称的编码器–解码器 U 形结构,通过跳跃连接融合浅层细节与深层语义,成为医学图像(含超声)分割的奠基架构。
- 在少量标注数据(ISBI 细胞追踪挑战赛)上实现端到端训练,解决医学场景标注稀缺问题。
- 挑战:超声图像存在散斑噪声、低对比度、探头依赖性强,原始 U-Net 对复杂超声场景泛化有限,后续大量改进工作基于此展开。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 2D 医学图像(如超声 B 模图像,尺寸可变) | 逐像素语义分割掩码(与输入同分辨率) |
实验方法
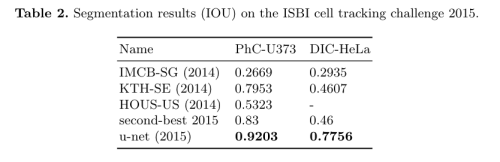
- 数据集:(1)ISBI 2012 EM 分割挑战赛:果蝇 VNC 连续切片 TEM 图像,30 张 512×512 训练图,二值标注(细胞/膜);(2)ISBI Cell Tracking Challenge 2014/2015:PhC-U373 胶质瘤细胞相差显微镜 35 张部分标注图;DIC-HeLa 微分干涉对比显微镜 20 张部分标注图。
- 数据划分:EM 使用官方 30 张训练集,测试集标注保密;细胞追踪任务遵循挑战赛既定划分。
- 预处理与增强:valid 卷积(无 padding);大图推理采用 overlap-tile + 边界镜像填充;EM 测试时对输入做 7 个旋转版本预测取平均;细胞任务引入分离边界与逐像素权重图(w₀=10,σ≈5 px);随机弹性形变(3×3 粗网格位移,高斯 σ=10);收缩路径末端 Drop-out。
- 网络与训练:23 层 U 形全卷积网络(3×3 卷积 + ReLU + 2×2 max-pool;扩展路径 2×2 up-conv + skip 拼接);Caffe + SGD,batch=1,momentum=0.99;权重初始化 N(0, √(2/N));Nvidia Titan GPU 约 10 小时完成训练。
- 损失函数:逐像素 softmax 交叉熵 + 加权损失 E=Σ w(x)log(p(x)),w(x) 结合类别频率与到细胞边界的距离。
- 评估指标:EM 任务在 10 个阈值下报告 Warping Error、Rand Error、Pixel Error;细胞任务报告 IoU。
- 对比基线:EM 对比 DIVE、DIVE-SCI、IDSIA 滑动窗口 CNN 等;细胞任务对比 IMCB-SG、KTH-SE、HOUS-US 等 2014/2015 挑战赛方法。
摘要(中文)
我们提出一种全卷积网络 U-Net,用于生物医学图像的像素级分割。网络由收缩路径(编码器)和扩张路径(解码器)组成,二者通过跳跃连接结合,使网络能够利用上下文信息的同时保留高分辨率定位信息。该架构在 ISBI 细胞追踪挑战赛中,仅用 30 张标注图像训练即可超越先前方法,并可在更大规模数据集上快速收敛,成为生物医学图像分割的通用基线方法。
框图
对比实验结果
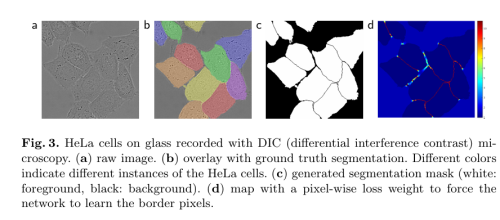
1.2 EchoNet-Dynamic(2020)
| 字段 | 内容 |
|---|---|
| 文章名称 | Video-based AI for beat-to-beat assessment of cardiac function |
| 作者与机构 | David Ouyang, Bryan He, Amirata Ghorbani 等;斯坦福大学(Stanford University) |
| 发布时间 | 2020 年 3 月(Nature) |
| 发布地址 | https://echonet.github.io/dynamic/ |
| 论文地址 | https://doi.org/10.1038/s41586-020-2145-8 |
| GitHub 地址 | https://github.com/echonet/dynamic |
主要工作与挑战
- 发布 EchoNet-Dynamic 数据集(10,030 例心超视频),含射血分数(EF)、左心室容积及专家描记标注。
- 采用 3D CNN(R2+1D、R3D、MC3)实现左心室语义分割、EF 预测及心肌病评估,达到与专家相当的精度。
- 挑战:超声视频帧间运动大、心搏周期变化、探头角度差异;需处理长时序依赖与 beat-to-beat 变异性。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 心超四腔心切面视频(AVI/DICOM,可变帧数) | 左心室分割掩码、EF 值、心肌病分类结果 |
实验方法
- 数据集:EchoNet-Dynamic,Stanford 单中心 10,030 例 apical-4-chamber 心超视频(去标识化 AVI),含专家标注的 EF、EDV、ESV 及左心室心内膜/心外膜描记;覆盖正常、低 EF、心律失常等典型采集条件。
- 数据划分:按患者级别划分训练/验证/测试(论文采用固定随机种子划分,避免同一患者泄漏)。
- 预处理:DICOM→AVI 转换与去标识;视频中心裁剪并缩放至 112×112;按帧提取并归一化像素强度。
- 模型架构:3D CNN 系列——R2+1D-18/34、R3D-18/34、MC3-18/34;三任务流水线:(1)逐帧左心室语义分割;(2)由分割掩码计算容积并预测 EF(整段视频或子片段);(3)基于 beat-to-beat EF 评估心肌病(EF<40%)。
- 训练设置:Adam 优化器;batch size 20;训练约 45 epochs;分割任务用 Dice + 交叉熵组合损失;EF 回归用 MAE 损失。
- 评估指标:分割 Dice;EF 预测 MAE、RMSE(与专家测量对比,Bland-Altman 分析);心肌病分类 AUC。
- 对比基线:与高级心脏超声医师标注/测量对比;不同 3D CNN 架构(R2+1D vs R3D vs MC3)内部消融。
摘要(中文)
医学视频分析进展远落后于静态图像,主要瓶颈在于缺乏公开的大规模标注视频数据。我们发布包含 10,030 例心超视频的 EchoNet-Dynamic 数据集,涵盖 EF、左心室容积及专家描记。基于 3D 卷积网络,模型可逐帧分割左心室、预测 EF,性能与专家人类相当。这是目前最大的公开标注医学视频数据集,为超声视频智能分析提供了重要基准。
框图位置
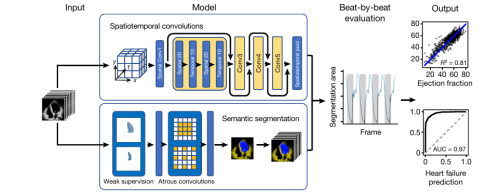
1.3 nnU-Net(2020/2021)
| 字段 | 内容 |
|---|---|
| 文章名称 | nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation |
| 作者与机构 | Fabian Isensee, Paul F. Jäger, Simon A. A. Kohl 等;德国癌症研究中心(DKFZ) |
| 发布时间 | 2020 年 12 月在线,2021 年 2 月(Nature Methods) |
| 发布地址 | https://www.nature.com/articles/s41592-020-01008-z |
| 论文地址 | https://doi.org/10.1038/s41592-020-01008-z |
| GitHub 地址 | https://github.com/MIC-DKFZ/nnUNet |
主要工作与挑战
- 提出"自配置"分割框架:自动分析数据集指纹(分辨率、体素间距、强度分布等),自适应选择预处理、网络拓扑、训练策略与后处理。
- 在 23 个国际生物医学分割竞赛数据集上超越大量手工定制方案,成为 MICCAI 挑战赛主流基线。
- 挑战:超声数据各向异性、噪声大、标注不一致;nnU-Net 需针对超声数据集进行指纹分析与配置验证。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 2D/3D 医学图像(含超声),NIfTI/npz 等格式 | 逐体素/逐像素语义分割掩码 |
实验方法
- 数据集:23 个国际生物医学分割竞赛公开数据集(覆盖 MRI、CT、显微镜、超声等多模态),含 Medical Segmentation Decathlon、KiTS、LiTS 等经典 benchmark。
- 自配置流程:(1)指纹提取——分析图像尺寸、体素间距、强度分布、类别数等;(2)实验规划——自动选择 2D/3D U-Net 变体(2d、3d_fullres、3d_lowres、3d_cascade_fullres)及 patch 大小、batch size;(3)预处理——重采样、归一化、裁剪策略自动确定;(4)后处理——连通域分析等。
- 训练协议:每个配置默认 5 折交叉验证;训练至收敛(通常 1000 epochs,带早停);默认 SGD + Nesterov momentum;数据增强含旋转、缩放、弹性形变、镜像等(依数据集指纹自动启用)。
- 集成策略:5 折模型预测概率平均;可选跨配置 ensemble(2d + 3d_fullres 等组合);
find_best_configuration自动选最优配置与后处理。 - 评估指标:各竞赛标准指标,主要为 Dice;部分数据集报告 HD95、NSD、IoU 等。
- 对比基线:23 个数据集上各竞赛手工定制 SOTA 与通用 U-Net 默认配置;nnU-Net 在多数数据集取得第一或并列第一排名。
摘要(中文)
生物医学图像分割算法的设计高度依赖数据集特性与硬件条件,非专家难以获得最优性能。我们提出 nnU-Net,一种能够自动配置预处理、网络架构、训练和后处理的深度分割方法。关键设计选择被建模为固定参数、相互依赖规则与经验决策的组合。无需人工干预,nnU-Net 在 23 个公开竞赛数据集上超越大多数现有方法。我们将其作为开箱即用工具公开,使最先进分割技术对广大用户可及。
框图
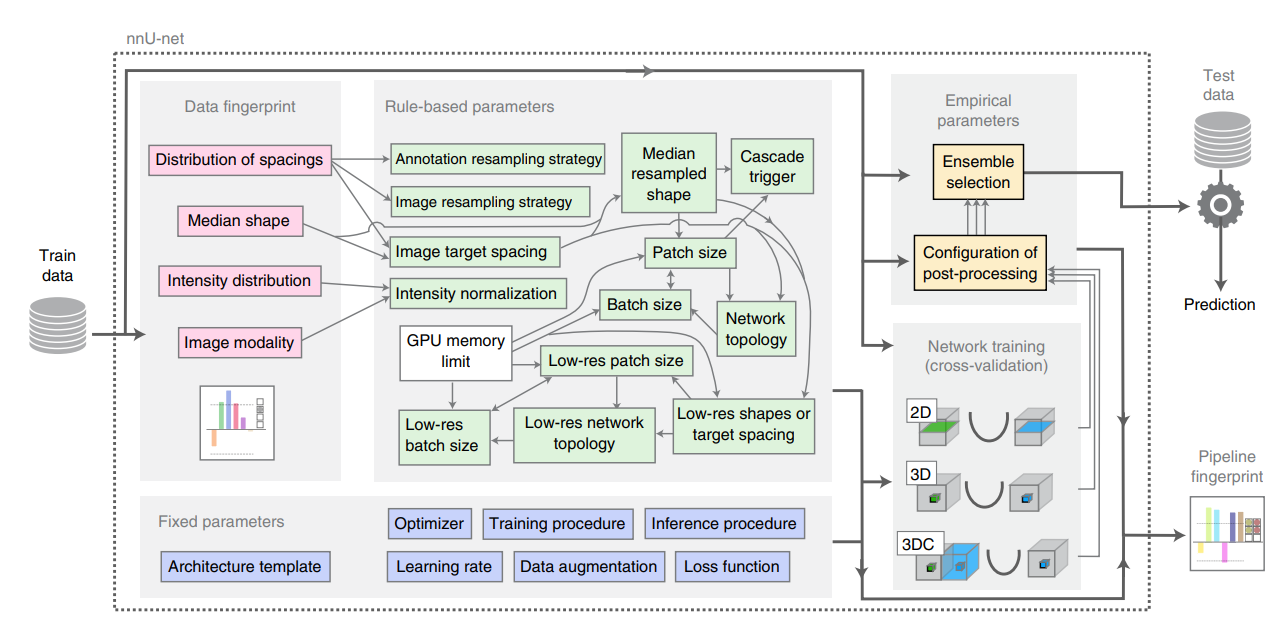
1.4 SAM-Med2D(2023)
| 字段 | 内容 |
|---|---|
| 文章名称 | SAM-Med2D |
| 作者与机构 | Junlong Cheng, Jin Ye, Zhongying Deng 等;OpenGVLab / 上海人工智能实验室等 |
| 发布时间 | 2023 年 8 月(arXiv) |
| 发布地址 | https://huggingface.co/papers/2308.16184 |
| 论文地址 | https://arxiv.org/abs/2308.16184 |
| GitHub 地址 | https://github.com/OpenGVLab/SAM-Med2D |
主要工作与挑战
- 构建 SA-Med2D-20M 大规模医学分割数据集(460 万张图像、1970 万个掩码,覆盖 10 种模态含超声)。
- 对 Segment Anything Model(SAM)进行 encoder + decoder 全面微调,支持点、框、掩码多种提示。
- 挑战:SAM 在自然图像上预训练,直接迁移至超声模态性能大幅下降(超声 Dice 约 15.89 vs SAM 基线);需领域自适应与大规模微调。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 2D 医学图像 + 交互提示(点/框/掩码) | 目标区域分割掩码 |
实验方法
- 数据集:自构建 SA-Med2D-20M——460 万张图像、1970 万个掩码,覆盖 10 种模态(含 Ultrasound、CT、MR、X-ray 等)、4 类解剖结构 + 病灶、31 个主要器官;训练集用于微调,9 个 MICCAI 2023 挑战赛数据集用于外部泛化测试。
- 模型与微调:以 SAM(ViT-H) 为基座,同时微调 Image Encoder 与 Mask Decoder(较 MedSAM 等仅微调 decoder 更全面);支持 点、框、掩码 三种交互提示的统一训练。
- 训练设置:AdamW 优化器;学习率 1e-4;batch size 2;训练 200 epochs;多 GPU 分布式训练;损失为 SAM 原始 focal loss + dice loss 组合。
- 评估协议:按模态(Ultrasound/MRI/CT 等)、解剖结构、器官类别分层报告;零样本 SAM vs 微调 SAM-Med2D 对比;在 9 个外部数据集上不微调直接测试泛化。
- 评估指标:Dice、IoU、NSD(Normalized Surface Dice);超声模态单独报告(SAM 零样本超声 Dice 约 15.89,微调后大幅提升)。
- 对比基线:原始 SAM、MedSAM、仅微调 decoder 的变体、不同提示类型(点/框/掩码)消融。
摘要(中文)
Segment Anything Model(SAM)在自然图像分割中表现优异,但直接应用于医学图像效果不佳,主要源于自然图像与医学图像之间的显著域差距。我们提出 SAM-Med2D,在约 460 万张图像和 1970 万个掩码构成的大规模医学数据集上进行全面微调,涵盖多种模态和解剖结构。与仅使用框或点提示的先前方法不同,我们采用更全面的提示策略并微调 encoder 与 decoder。在多种模态、解剖结构和器官上的评估表明,SAM-Med2D 相比 SAM 具有显著更优的性能和泛化能力。
框图位置
1 | ┌─────────────────────────────────────────────────────────┐ |
1.5 超声分割系统综述(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | Deep Learning-Based Medical Ultrasound Image and Video Segmentation Methods: Overview, Frontiers, and Challenges |
| 作者与机构 | 见原文作者列表;发表于 Sensors(MDPI) |
| 发布时间 | 2025 年 4 月 |
| 发布地址 | https://www.mdpi.com/1424-8220/25/8/2361 |
| 论文地址 | https://doi.org/10.3390/s25082361 |
| GitHub 地址 | 无官方代码(综述类文章) |
主要工作与挑战
- 系统回顾 80+ 篇超声图像/视频分割文献,涵盖 CNN、Transformer、扩散模型、SAM 等范式。
- 按方法特性分为四类,总结评估指标(Dice、IoU、HD95 等)与常用公开数据集。
- 挑战:超声散斑噪声、伪影、探头依赖、标注稀缺、跨设备/跨中心泛化困难。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 综述类文章,不涉及具体模型 I/O | 方法分类、数据集汇总、性能对比与趋势分析 |
摘要(中文)
超声图像和视频中的复杂成像结构、伪影和噪声给精确分割带来重大挑战。深度学习已成为医学图像处理的重要方向。本文综述基于深度学习的超声图像和视频分割方法,总结扩散模型、Segment Anything 模型及经典方法的最新进展。方法按分割特性分为四大类,每类在对应章节中阐述和评估。我们提供全面的方法概述、评估指标和常用超声数据集介绍,分析各方法优缺点,并讨论挑战与未来趋势。
1.6 超声 AI 综合综述(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | Artificial Intelligence in Ultrasound Imaging: A Comprehensive Review |
| 作者与机构 | 见原文作者列表;发表于 AUDT(Advanced Ultrasound in Diagnosis and Therapy) |
| 发布时间 | 2025 年 |
| 发布地址 | https://www.sciopen.com/article/10.26599/AUDT.2025.250104 |
| 论文地址 | https://www.sciopen.com/local/article_pdf/10.26599/AUDT.2025.250104.pdf |
| GitHub 地址 | 无官方代码(综述类文章) |
主要工作与挑战
- 全面回顾 AI 在超声成像中的应用,从传统机器学习到深度学习及 LLM 多模态方法。
- 涵盖分割、分类、检测、报告生成等任务,讨论数据集构建、可解释性与临床转化。
- 挑战:标注数据有限、模型可解释性不足、多中心临床环境适配、LLM 与视觉模型融合的安全性问题。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 综述类文章 | 任务分类、方法演进路线图、临床应用场景分析 |
摘要(中文)
人工智能在超声成像中的应用正从传统机器学习向深度学习及大语言模型驱动的多模态分析演进。本文全面回顾 AI 在超声中的关键任务,包括分割、分类、检测和报告生成,重点介绍方法创新、临床应用及当前挑战。我们讨论了大规模数据集构建、多模态基础模型、可解释性提升及临床转化等未来方向,为智能超声研究提供系统性参考。
2 3DGS 系列(含 NeRF)
本节按时间顺序梳理神经辐射场(NeRF)至 3D Gaussian Splatting 及其主要变体,涵盖静态/动态场景重建与实时渲染。
2.1 NeRF(2020)
为什么放NeRF呢,因为3DGS踩着NeRF开创了3D重建的盛世天下。
| 字段 | 内容 |
|---|---|
| 文章名称 | NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis |
| 作者与机构 | Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik 等;UC Berkeley / Google Research / UC San Diego |
| 发布时间 | 2020 年 3 月(ECCV 2020 Oral,Best Paper Honorable Mention) |
| 发布地址 | https://www.matthewtancik.com/nerf |
| 论文地址 | https://arxiv.org/abs/2003.08934 |
| GitHub 地址 | https://github.com/bmild/nerf |
主要工作与挑战
- 提出神经辐射场(NeRF):用 MLP 将 5D 坐标(空间位置 + 视角方向)映射为体密度和视角相关颜色,通过可微体渲染合成新视角。
- 引入位置编码(Positional Encoding)与分层采样,实现高保真新视角合成。
- 挑战:训练慢(每场景数小时)、渲染慢(非实时)、无法编辑/导出显式几何;为后续 3DGS 等显式表示奠定基础。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角 RGB 图像 + 已知相机位姿 | 任意新视角的高保真 RGB 渲染图像 |
实验方法
- 数据集:(1)Synthetic NeRF (Blender):8 个合成场景,800×800,100 训练 + 200 测试视角;(2)LLFF:8 个真实前向场景(fern、flower 等),约 20–62 张图像;(3)DTU:15 个扫描场景;(4)Tanks & Temples:5 个室外大场景。
- 相机位姿:合成数据使用 Blender 导出精确位姿;真实数据使用 LLFF 的 COLMAP/SfM 位姿估计。
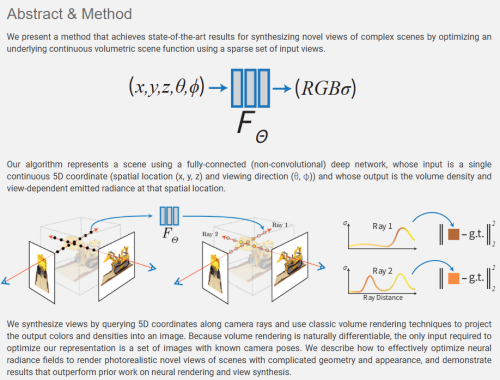
- 网络结构:8 层 MLP(256 宽,ReLU),输入 5D 坐标 (x,y,z,θ,φ);位置编码 γ(L=10) 用于坐标、γ(L=4) 用于视角;输出体密度 σ 与视角相关 RGB。
- 体渲染与采样:每条光线 64 粗采样 + 128 细采样(基于粗网络密度分布);可微体渲染积分得到像素颜色。
- 训练设置:Adam,lr=5e-4 衰减至 5e-5;每场景 200k–300k 迭代;单场景约 1–2 张 V100 GPU 天。
- 评估指标:PSNR↑、SSIM↑、LPIPS↓(VGG 特征)。
- 对比基线:SRN、LLFF、Neural Volumes、NSVF、AutoInt 等;在 Synthetic 与 LLFF 上全面超越先前方法。
摘要(中文)
我们提出一种通过优化连续体素场景函数来实现高质量新视角合成的方法。算法使用全连接深度网络表示场景,输入为 5D 坐标(空间位置 x,y,z 和视角方向 θ,φ),输出为该位置的体密度和视角相关辐射度。沿相机光线查询 5D 坐标,利用经典体渲染技术将颜色和密度投影为图像。由于体渲染天然可微,仅需已知位姿的多视角图像即可优化。实验表明,NeRF 在复杂几何和外观场景的新视角合成上超越先前神经渲染方法。
2.2 3D Gaussian Splatting(2023)
| 字段 | 内容 |
|---|---|
| 文章名称 | 3D Gaussian Splatting for Real-Time Radiance Field Rendering |
| 作者与机构 | Bernhard Kerbl*, Georgios Kopanas*, Thomas Leimkühler, George Drettakis;INRIA / Université Côte d’Azur(* 同等贡献) |
| 发布时间 | 2023 年 7 月(SIGGRAPH 2023) |
| 发布地址 | https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/ |
| 论文地址 | https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/3d_gaussian_splatting_high.pdf |
| GitHub 地址 | https://github.com/graphdeco-inria/gaussian-splatting |
主要工作与挑战
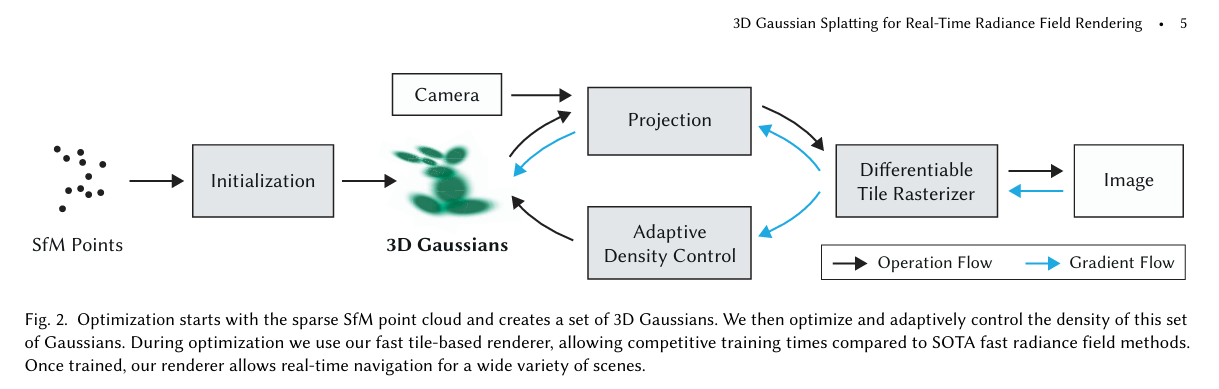
- 用 3D 高斯椭球体显式表示场景,每个高斯含位置、协方差、不透明度、球谐系数(颜色)。
- 设计可微高斯光栅化,实现 ≥30 FPS 实时渲染,训练约 30 分钟收敛。
- 挑战:多视角不一致导致几何模糊、缩放/变焦时走样(aliasing)、高斯数量膨胀、动态场景需扩展。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角 RGB 图像 + COLMAP 估计的相机位姿 | 实时新视角 RGB 渲染;可导出 3D 高斯点云 |
实验方法
- 数据集:(1)Mip-NeRF 360:9 个无界/室内真实场景;(2)Tanks & Temples:Train、Truck 共 2 场景;(3)Deep Blending:DrJohnson、Playroom 共 2 场景;(4)Blender Synthetic NeRF:8 个合成场景。共 13 个真实场景 + 8 合成场景。
- 初始化:COLMAP SfM 估计相机位姿;从稀疏点云初始化 3D 高斯(位置、各向同性协方差=到最近 3 点平均距离、SH 颜色、不透明度)。
- 训练设置:默认 30,000 迭代(报告 Ours-7K 与 Ours-30K 两配置);SGD 优化;损失 L = (1−λ)L₁ + λ·D-SSIM,λ=0.2;分辨率 warm-up(1/4 分辨率起始,250/500 迭代上采样);SH 每 1000 迭代增加 1 频带至 4 阶。
- 密度控制:500–15000 迭代每 100 步执行 clone/split/prune;梯度阈值 0.0002;每 3000 步 opacity 重置;大高斯 split(φ=1.6)、小高斯 clone。
- 评估协议:遵循 Mip-NeRF360,每 8 张取 1 张作测试;图像宽度 >1600 px 自动缩放。
- 评估指标:PSNR↑、SSIM↑、LPIPS↓;另报告训练时间、渲染 FPS、模型存储 Mem。
- 硬件:NVIDIA A6000(>20 GB 峰值显存);Mip-NeRF360 基线复现需 4×A100 训练 12 h。
- 对比基线:Mip-NeRF 360、Instant-NGP (Base/Big)、Plenoxels;合成集额外对比 Mip-NeRF、Point-NeRF。
摘要(中文)
辐射场方法在 novel view synthesis 上取得高质量结果,但训练与渲染代价高。3D 高斯光栅化(3DGS)用 3D 高斯集合表示场景,配合可微光栅化管道,在保持视觉质量的同时实现实时渲染。引入自适应密度控制(克隆/分裂/修剪),使高斯数量与场景复杂度匹配。在 Mip-NeRF 360、Tanks & Temples 等数据集上达到 SOTA 或可比质量,渲染速度提升数个数量级。
2.3 Mip-Splatting(2023/2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | Mip-Splatting: Alias-free 3D Gaussian Splatting |
| 作者与机构 | Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, Andreas Geiger;University of Tübingen / Tübingen AI Center / ShanghaiTech / CTU Prague |
| 发布时间 | 2023 年 11 月 arXiv,2024 年 6 月(CVPR 2024 Oral,Best Student Paper) |
| 发布地址 | https://niujinshuchong.github.io/mip-splatting/ |
| 论文地址 | https://arxiv.org/abs/2311.16493 |
| GitHub 地址 | https://github.com/autonomousvision/mip-splatting |
主要工作与挑战
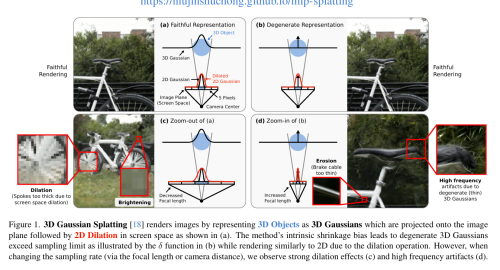
- 针对 3DGS 在变焦/变距时的走样与闪烁问题,引入 3D 平滑滤波器(约束高斯频率)和 2D Mip 滤波器(替代 dilation)。
- 实现任意尺度的无走样渲染,训练单尺度、测试多尺度场景表现优异。
- 挑战:滤波器参数选择、与原始 3DGS 密度控制的兼容性、大场景扩展。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角 RGB 图像 + 相机位姿(可与 3DGS 相同) | 任意缩放因子下的无走样新视角渲染 |
实验方法
- 数据集:与 3DGS 相同——Mip-NeRF 360、Tanks & Temples、Deep Blending 全部场景;额外设计单尺度训练、多尺度测试(zoom-in/zoom-out)实验验证走样消除。
- 方法改动:在 3DGS 基础上增加(1)3D 平滑滤波器——约束高斯最大频率不超过训练视角 Nyquist 极限;(2)2D Mip 滤波器——替代原始 dilation,模拟 1 px 盒式滤波(方差 0.1),3D 平滑滤波方差 0.2。
- 训练设置:基于官方 3DGS 代码库;30K 迭代;其余超参与 3DGS 一致;每 100 迭代重算各高斯采样率。
- 评估协议:标准 novel view synthesis(PSNR/SSIM/LPIPS);多尺度渲染——训练固定焦距,测试不同 zoom factor(0.25×–4×)观察走样/闪烁。
- 评估指标:PSNR↑、SSIM↑、LPIPS↓;多尺度场景重点关注高频伪影与边缘稳定性。
- 对比基线:3DGS、3DGS+EWA filter;在 out-of-distribution 相机距离/焦距下 Mip-Splatting 显著优于 3DGS。
摘要(中文)
3D 高斯光栅化在新视角合成上达到高保真与高效率,但在改变采样率(如变焦或改变相机距离)时会出现明显走样。我们发现原因包括缺乏 3D 频率约束和使用 2D dilation 滤波器。为此引入 3D 平滑滤波器,根据输入视角的最大采样频率约束 3D 高斯尺寸,消除放大时的高频伪影;同时将 2D dilation 替换为模拟 2D 盒式滤波的 Mip 滤波器,有效缓解走样。在单尺度训练、多尺度测试等场景下验证了方法有效性。
框图位置
1 |
1 | ┌─────────────────────────────────────────────────────────┐ |
2.4 2D Gaussian Splatting(2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | 2D Gaussian Splatting for Geometrically Accurate Radiance Fields |
| 作者与机构 | Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, Shenghua Gao;ShanghaiTech University / University of Tübingen |
| 发布时间 | 2024 年 3 月 arXiv,2024 年 7 月(SIGGRAPH 2024) |
| 发布地址 | https://surfsplatting.github.io/ |
| 论文地址 | https://arxiv.org/abs/2403.17888 |
| GitHub 地址 | https://github.com/hbb1/2d-gaussian-splatting |
主要工作与挑战
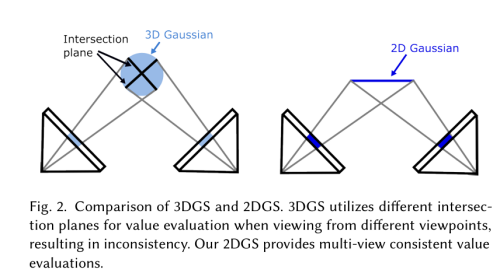
- 将 3D 高斯坍缩为 2D 定向圆盘(surfel),提供视角一致的几何表示,解决 3DGS 表面重建不准确问题。
- 引入透视正确的光线–面元求交光栅化,配合深度畸变损失和法向一致性损失。
- 挑战:非流形场景、薄结构重建、与 NeRF/3DGS 的外观质量权衡。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角 RGB 图像 + 相机位姿 | 新视角 RGB 渲染 + 高质量深度/法向/网格 |
实验方法
- 数据集:(1)Mip-NeRF 360、Tanks & Temples——新视角合成;(2)DTU——几何重建(Chamfer Distance);(3)作者提供的 DTU+COLMAP 预处理数据(3.5 GB)。
- 方法要点:2D 定向 surfel 替代 3D 椭球;透视正确光线–面元求交光栅化;额外损失:深度畸变损失 L_d + 法向一致性损失 L_n(从渲染深度图估计法向并与 surfel 法向对齐)。
- 训练设置:基于 3DGS 训练流程改造;30K 迭代;SGD + L1/D-SSIM 主损失 + λd·L_d + λn·L_n;密度控制策略与 3DGS 类似。
- 网格提取:渲染多视角深度图 → TSDF Fusion 或 Poisson 重建 → 提取 mesh;DTU 上与 NeuS、VolSDF 等 SDF 方法对比。
- 评估指标:渲染 PSNR/SSIM/LPIPS;几何 Chamfer Distance↓、Normal Consistency↑、F1-score(DTU)。
- 对比基线:3DGS、NeuS、VolSDF、Gaussian Opacity Fields;2DGS 在几何精度上显著优于 3DGS,渲染质量相当。
摘要(中文)
3D 高斯光栅化革新了辐射场重建,但 3D 高斯的多视角不一致性导致表面表示不准确。我们提出 2D 高斯光栅化(2DGS),将 3D 体素坍缩为一组 2D 定向平面高斯圆盘,提供视角一致的几何。引入透视正确的 2D splatting(光线–面元求交 + 光栅化),并加入深度畸变和法向一致性正则项。实验表明,2DGS 在无噪声几何重建上表现优异,同时保持竞争性外观质量、快速训练和实时渲染。
2.5 4D Gaussian Splatting(2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering |
| 作者与机构 | Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie 等;华中科技大学(HUST)等 |
| 发布时间 | 2023 年 10 月 arXiv,2024 年 6 月(CVPR 2024) |
| 发布地址 | https://guanjunwu.github.io/4dgs/ |
| 论文地址 | https://arxiv.org/abs/2310.08528 |
| GitHub 地址 | https://github.com/hustvl/4DGaussians |
主要工作与挑战
- 将 3DGS 扩展至 动态场景:用 3D 高斯 + 4D 神经体素(HexPlane 分解)表示时空变化。
- 轻量 MLP 预测高斯在新时间戳的形变,实现 800×800 分辨率 82 FPS 实时渲染。
- 挑战:长序列存储膨胀、复杂非刚性运动建模、与 NeRF 动态方法的精度对比。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角动态场景 RGB 视频 + 相机位姿 | 任意时间戳的新视角 RGB 渲染 |
实验方法
- 数据集:(1)D-NeRF(合成动态场景,8 场景);(2)HyperNeRF / Nerfies(真实动态场景,如 broom、apple 等);(3)Neural 3D Video (N3V) 部分场景。
- 表示与训练:3D 高斯 + HexPlane 分解的 4D 神经体素编码;轻量 MLP 预测各时间戳高斯位置/尺度/旋转/不透明度形变;初始 10 万高斯;训练 30K 迭代。
- 训练时间:D-NeRF 约 8 min/场景;HyperNeRF 约 30 min/场景(RTX 3090)。
- 评估协议:留一帧/稀疏时间戳测试;对比逐帧独立 3DGS 与动态 NeRF 方法。
- 评估指标:PSNR↑、SSIM↑、LPIPS↓;渲染速度 FPS(800×800 约 82 FPS,1352×1014 约 36 FPS)。
- 对比基线:D-NeRF、HyperNeRF、K-Planes、TiNeuVox 等动态 NeRF;4D-GS 在质量相当或更优的同时实现数量级加速。
摘要(中文)
动态场景表示与渲染是重要但充满挑战的任务,准确建模复杂运动的同时保持高效率通常难以兼顾。我们提出 4D 高斯光栅化(4D-GS),作为动态场景的整体表示而非逐帧 3DGS。方法包含 3D 高斯与 4D 神经体素的显式表示,采用 HexPlane 启发的分解神经体素编码构建高斯特征,轻量 MLP 预测新时间戳的高斯形变。4D-GS 在高分辨率下实现实时渲染(RTX 3090 上 800×800 约 82 FPS),质量与先前 SOTA 相当或更优。
2.6 FastGS(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | FastGS: Training 3D Gaussian Splatting in 100 Seconds |
| 作者与机构 | Shiwei Ren, Tianci Wen, Yongchun Fang, Biao Lu 等 |
| 发布时间 | 2025 年 11 月 arXiv,2026 年(CVPR 2026 Highlight) |
| 发布地址 | https://fastgs.github.io/ |
| 论文地址 | https://arxiv.org/abs/2511.04283 |
| GitHub 地址 | https://github.com/fastgs/FastGS |
主要工作与挑战
- 提出基于 多视角一致性 的加速框架:View-Consistent Densification(VCD)与 View-Consistent Pruning(VCP)。
- 无需 budget 机制即可精准控制高斯数量,Tanks & Temples 场景训练约 100 秒,Deep Blending 上较 vanilla 3DGS 加速 15.45×。
- 可泛化至动态重建、表面重建、稀疏视角、大场景与 SLAM 等任务(2–7× 加速)。
- 挑战:极速训练下的几何精度、与 Mip/2DGS 等变体结合时的稳定性。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 多视角 RGB 图像 + 相机位姿 | 快速训练后的 3D 高斯场景 + 实时新视角渲染 |
实验方法
- 数据集:Mip-NeRF 360(全场景)、Tanks & Temples(Train 等)、Deep Blending(Playroom、DrJohnson);另在动态重建、表面重建、稀疏视角、大场景、SLAM 等 6 类任务验证泛化。
- 核心方法:(1)VCD(View-Consistent Densification)——仅在多视角重建误差高的区域致密化;(2)VCP(View-Consistent Pruning)——剪除对多视角渲染无贡献的冗余高斯;无需 budget 机制。
- 训练设置:基于 vanilla 3DGS 代码改造;Tanks & Temples Train 场景约 100 秒完成;Deep Blending 较 3DGS 加速 15.45×;Mip-NeRF 360 加速 3.32×(vs DashGaussian)。
- 评估指标:PSNR↑、SSIM↑、LPIPS↓;训练时间↓、高斯数量 #Gaussian↓ 为核心效率指标。
- 对比基线:3DGS、Scaffold-GS、DashGaussian、Speedy-Splat、Taming-3DGS;FastGS-Big 在质量最优的同时仍快于先前 SOTA。
摘要(中文)
现有 3DGS 加速方法未能有效调控训练过程中的高斯数量,导致冗余计算开销。我们提出 FastGS,一种基于多视角一致性的简洁通用加速框架,通过多视角一致致密化(VCD)和剪枝(VCP)策略,无需 budget 机制即可高效平衡训练时间与渲染质量。在 Mip-NeRF 360、Tanks & Temples 和 Deep Blending 数据集上,FastGS 显著超越 SOTA 方法的训练速度,同时保持可比渲染质量,并在动态场景、表面重建、稀疏视角、大场景和 SLAM 等任务上展现强泛化性。
框图位置

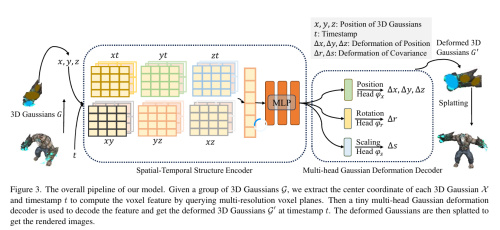
2.7 MedGS(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | MedGS: Learning 3D Structures from Sequential Medical Imaging with Gaussian Splatting |
| 作者与机构 | Kacper Marzol, Ignacy Kolton, Weronika Smolak-Dyżewska, Joanna Kaleta, Żaneta Świderska-Chadaj, Marcin Mazur, Mirosław Dziekiewicz, Tomasz Markiewicz, Przemysław Spurek;雅盖隆大学 / 华沙理工大学 / IDEAS Research Institute / Sano Centre for Computational Medicine / 波兰军事医学研究所等 |
| 发布时间 | 2025 年 9 月(arXiv) |
| 发布地址 | https://github.com/gmum/MedGS |
| 论文地址 | https://arxiv.org/abs/2509.16806 |
| GitHub 地址 | https://github.com/gmum/MedGS |
主要工作与挑战
- 提出首个面向 序列化医学影像(超声、MRI、CT)的 Gaussian Splatting 框架,用于高保真 3D 解剖结构重建。
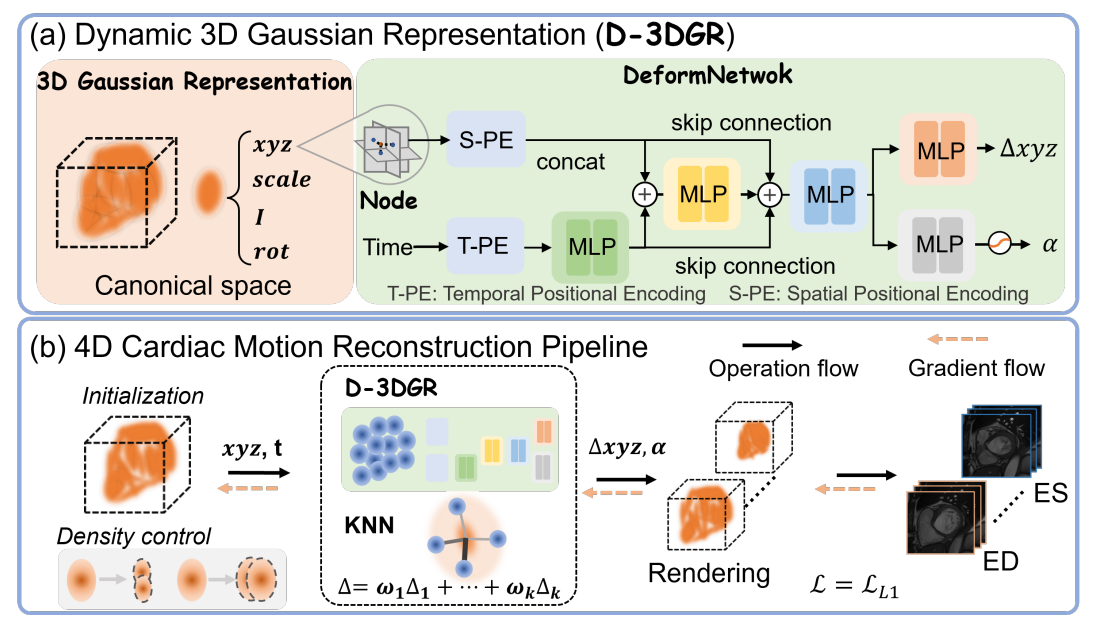
- 采用 多任务共享几何 架构:统一 Folded-Gaussian 几何表示,双颜色分支同时完成帧间插值(
c_img)与分割/网格重建(c_seg),图像分支的稠密信号正则化几何。 - 引入 In-Between Frame Regularization(IBFR) 机制,缓解稀疏切片间的噪声与采样不足问题。
- 基于 VeGaS 的 Folded-Gaussian 建模时序变化,支持从稀疏帧提取高质量网格(Marching Cubes)。
- 挑战:仅提供结构估计而非直接组织测量,存在固有不确定性;低对比度区域单任务变体(MedGSs)性能下降;临床部署需专家复核。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 序列化 2D 医学切片(灰度图 + 可选二值掩码)+ 时间戳 / 3D 空间位姿 | 插值中间帧、分割掩码、3D 器官网格(mesh) |
实验方法
- 数据集:(1)Prostate Ultrasound(MR→US Registration Challenge,specimens 65–70);(2)TotalSegmentator MRI(heart、lung、kidney 等);(3)Skull-Stripped T1 MRI;(4)CTA 纵向病例(主动脉瘤、肾肿瘤监测)。
- 模型变体:MedGS(双任务联合)、MedGSi(仅插值)、MedGSs(仅分割/网格);基于 VeGaS Folded-Gaussian,初始 10 万高斯分量;时间形变函数 f 为 7 阶多项式。
- 训练设置:PyTorch + NVIDIA A100;每对象约 20 min;λseg=0.001,λσ=0.001;损失 L_total = L_img + λseg·L_seg + λσ·L_σ;L_img 含 L1 + SSIM + IBFR 帧间正则(α~U(0.2,0.8) 合成中间帧)。
- 插值评估:leave-frame-out 协议——训练每 n 帧取 1 帧(n∈{2,3,5}),测试其余帧;对比 Linear 插值、Optical Flow;指标 PSNR↑、SSIM↑。
- 网格重建评估:对比 ISO-surface(Marching Cubes)、Poisson Reconstruction、FUNSR;指标 Chamfer Distance↓、HD95↓。
- 消融实验:移除 L_interp* 或 L_σ 单独/联合评估对插值 PSNR/SSIM 的影响;MedGS vs MedGSs 验证双任务耦合收益。
摘要(中文)
超声、MRI 和 CT 等多模态三维医学影像广泛用于无创解剖可视化,但准确建模依赖表面重建与帧间插值,传统方法在图像噪声和稀疏帧之间信息不完整时表现不佳。我们提出 MedGS,一种基于 Gaussian Splatting 的高保真 3D 解剖重建框架。MedGS 采用多任务架构,通过统一几何表示同时执行帧插值与分割,利用图像合成的稠密信号正则化几何,即使输入帧数量有限也能实现高质量表面提取。医学数据被建模为具有双颜色属性的 Folded-Gaussian,并辅以帧间正则化(IBFR)机制。实验表明,MedGS 在隐式神经表示方法上取得更高指标分数,并改善插值质量。
框图位置
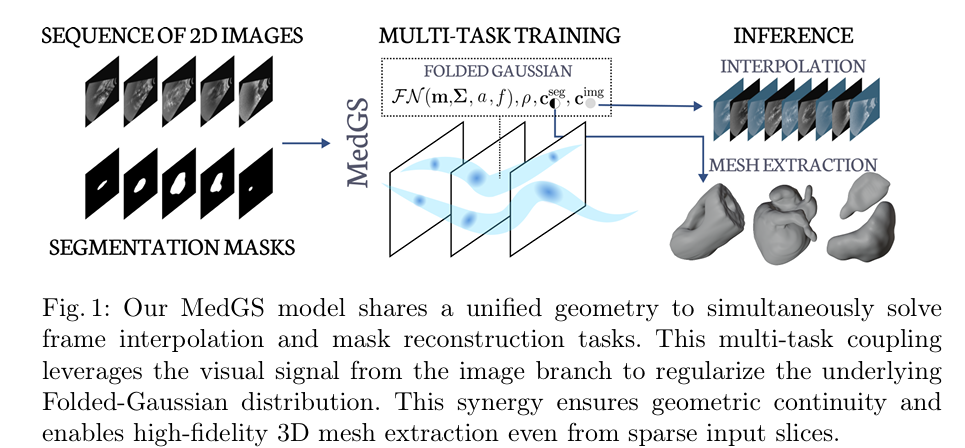
2.8 3DGS 综合综述(2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | 3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities |
| 作者与机构 | Yanqi Bao, Tianyu Ding, Jing Huo, Yaoli Liu, Yuxin Li, Wenbin Li, Yang Gao, Jiebo Luo;中国科学技术大学 / 哈尔滨工业大学 / 南京大学等 |
| 发布时间 | 2024 年 7 月(arXiv,v2 更新于 2024 年 12 月) |
| 发布地址 | https://arxiv.org/abs/2407.17418 |
| 论文地址 | https://arxiv.org/abs/2407.17418 |
| GitHub 地址 | 无官方代码(综述类文章;可参考社区资源 https://github.com/MrNeRF/awesome-3D-gaussian-splatting) |
主要工作与挑战
- 从任务、技术、挑战与机遇多视角系统梳理 3DGS 相关研究,帮助新人快速入门并辅助研究者归纳现有技术路线。
- 深入分析 3DGS 的优化、应用与扩展,按研究动机分类;总结 9 类技术模块及对应改进方向。
- 归纳跨任务共性挑战(渲染质量、几何精度、动态场景、压缩存储等)与潜在研究机会。
- 挑战:3DGS 领域论文爆发式增长,综述需持续更新;不同变体(2DGS、4DGS、SLAM 等)标准不统一。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 综述类文章,不涉及具体模型 I/O | 技术分类体系、方法对比、挑战分析与未来方向 |
摘要(中文)
3D 高斯光栅化(3DGS)已成为具有主流潜力的新视角合成与 3D 表示方法,可通过高效训练将多视角图像转为显式 3D 高斯表示,并实现实时渲染。本综述从交叉视角分析现有 3DGS 相关工作,涵盖相关任务、技术、挑战与机遇,旨在帮助新人快速理解该领域并辅助研究者系统整理现有技术与难点。我们深入探讨 3DGS 的优化、应用与扩展并按侧重点分类,总结现有工作中 9 类技术模块及改进;在此基础上进一步分析跨任务共性挑战与技术,提出潜在研究方向。
3 LLM 及医学超声 LLM 自主性
本节按时间顺序梳理通用 LLM 基础、医学领域 LLM 及超声场景下的视觉-语言模型与具身自主系统。
3.1 LLaMA(2023)
| 字段 | 内容 |
|---|---|
| 文章名称 | LLaMA: Open and Efficient Foundation Language Models |
| 作者与机构 | Hugo Touvron, Thibaut Lavril, Gautier Izacard 等;Meta AI |
| 发布时间 | 2023 年 2 月 |
| 发布地址 | https://arxiv.org/abs/2302.13971 |
| 论文地址 | https://arxiv.org/abs/2302.13971 |
| GitHub 地址 | https://github.com/meta-llama/llama(后续版本);原始:https://github.com/facebookresearch/llama |
主要工作与挑战
- 发布 7B–65B 参数的开源基础语言模型系列,仅使用公开数据集训练。
- LLaMA-13B 在多数基准上超越 GPT-3(175B),LLaMA-65B 与 Chinchilla-70B、PaLM-540B 竞争。
- 挑战:医学/超声领域需进一步微调;幻觉、安全性、多模态能力需 VLM 扩展。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 文本 token 序列(prompt) | 续写文本(completion) |
实验方法
- 预训练数据:仅使用公开数据集——CommonCrawl、C4、GitHub、Wikipedia、Books、ArXiv、StackExchange 等;总计约 1.0T–1.4T tokens(依模型规模)。
- 模型规模:LLaMA-7B/13B/33B/65B 四个版本;Transformer decoder-only;RoPE 位置编码;SwiGLU 激活;Pre-norm 结构。
- 训练设置:AdamW;cosine 学习率调度;warmup 2000 steps;序列长度 2048;在 2048×A100-80G 上训练(65B 约 21 天)。
- 评估基准(零样本/少样本):MMLU、HellaSwag、PIQA、WinoGrande、ARC、OpenBookQA、BoolQ 等 20+ 基准;主要指标为 Accuracy。
- 关键结果:LLaMA-13B 在多数基准超越 GPT-3 (175B);LLaMA-65B 与 Chinchilla-70B、PaLM-540B 竞争;LLaMA-7B 可在单张 GPU 运行。
- 对比基线:GPT-3、OPT、BLOOM、GLM、Chinchilla 等 contemporaneous LLM。
摘要(中文)
我们介绍 LLaMA,一系列 70 亿至 650 亿参数的基础语言模型。模型在数万亿 token 上训练,证明仅使用公开可用数据集即可训练出最先进模型,无需依赖专有数据。LLaMA-13B 在多数基准上超越 GPT-3(175B),LLaMA-65B 与最佳大模型竞争。我们将所有模型发布给研究社区,促进 LLM 研究的民主化。
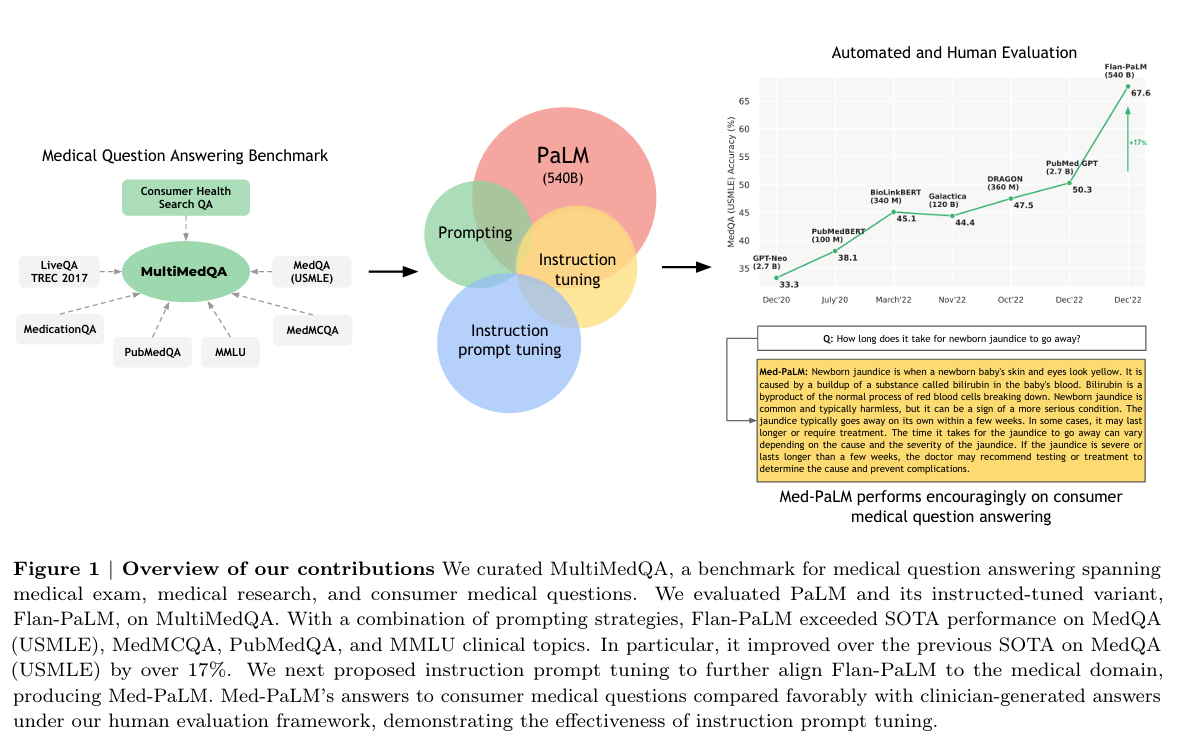
3.2 Med-PaLM(2022/2023)
| 字段 | 内容 |
|---|---|
| 文章名称 | Large Language Models Encode Clinical Knowledge(Med-PaLM) |
| 作者与机构 | Karan Singhal, Shekoofeh Azizi, Tao Tu 等;Google Research |
| 发布时间 | 2022 年 12 月 arXiv,2023 年 7 月(Nature) |
| 发布地址 | https://sites.research.google/med-palm/ |
| 论文地址 | https://arxiv.org/abs/2212.13138 |
| GitHub 地址 | 无公开代码(Google Research 项目) |
主要工作与挑战
- 提出 MultiMedQA 基准(6 个医学 QA 数据集 + HealthSearchQA),系统评估 LLM 临床知识。
- 提出 instruction prompt tuning,将 Flan-PaLM(540B)对齐至医学领域,得到 Med-PaLM。
- Med-PaLM 在 MedQA(USMLE 风格)上达 67.6% 准确率,首次超过"及格线";长回答与临床共识对齐度 92.6%。
- 挑战:仍低于临床医生水平;有害回答风险需持续降低;未覆盖超声影像多模态。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 医学选择题 / 消费者健康问答(文本) | 答案选择 / 长形式医学回答 |
实验方法
- 评估基准 MultiMedQA(7 数据集):MedQA (USMLE)、MedMCQA、PubMedQA、MMLU 临床子集、LiveQA、MedicationQA、新建 HealthSearchQA(3375 条网络健康搜索问题)。
- 模型:PaLM 540B → 指令微调 Flan-PaLM 540B → instruction prompt tuning 得 Med-PaLM 540B(冻结 backbone,仅训练 1.84M soft prompt 参数,100 tokens 长度,40 个临床医生撰写示范,200 steps AdamW)。
- MCQ 提示策略:5-shot / 3-shot few-shot + Chain-of-Thought + Self-Consistency(11 条推理路径多数投票);MedQA 上 SC 将 Flan-PaLM 从 60.3% 提升至 67.6%。
- 长答案人工评估:HealthSearchQA 100 + LiveQA 20 + MedicationQA 20 = 140 题;9 名临床医生盲评 12 个轴(科学共识、伤害程度/可能性、理解/检索/推理正确性、偏见等);5 名非专家评估有用性与意图匹配。
- 评估指标:MCQ Accuracy;长答案人工评分比例(aligned with consensus、potential harm 等)。
- 对比基线:PubMedGPT、BioGPT、Galactica、DRAGON 等;Med-PaLM 长答案共识对齐 92.6%(接近医生 92.9%),潜在伤害率 5.8%(接近医生 6.5%)。
摘要(中文)
大语言模型展示了令人印象深刻的能力,但医学临床应用的门槛很高。我们提出 MultiMedQA 基准和人类评估框架(涵盖事实性、理解力、推理、潜在危害和偏见等维度)。基于 Flan-PaLM,通过 instruction prompt tuning 构建 Med-PaLM。Med-PaLM 在 MedQA 上达 67.6% 准确率,超越先前 SOTA 17% 以上。人类评估显示 Med-PaLM 长回答的临床共识对齐度(92.6%)接近医生(92.9%),潜在危害率(5.8%)也与医生(6.5%)相当,但仍有改进空间。
框图位置
3.3 GPT-4 Technical Report(2023)
| 字段 | 内容 |
|---|---|
| 文章名称 | GPT-4 Technical Report |
| 作者与机构 | OpenAI |
| 发布时间 | 2023 年 3 月 |
| 发布地址 | https://openai.com/research/gpt-4 |
| 论文地址 | https://arxiv.org/abs/2303.08774 |
| GitHub 地址 | 无公开代码(API 服务) |
主要工作与挑战
- 发布大规模多模态模型 GPT-4,接受图像和文本输入,输出文本。
- 在 MMLU(86.4%)、Bar Exam(Top 10%)等专业基准上达到人类水平。
- 经 RLHF 对齐,提升事实性和指令遵循能力。
- 挑战:闭源、医学场景幻觉与安全风险、超声影像需专用 VLM 扩展。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 文本 prompt / 文本+图像(多模态) | 文本回复 |
实验方法
- 模型训练:大规模 Transformer 预训练(预测下一 token)+ RLHF 后训练对齐(提升事实性与指令遵循);具体架构与训练数据规模未公开。
- 评估基准(文本):MMLU (86.4%)、HellaSwag (95.3%)、ARC Challenge (96.3%)、HumanEval (67.0%)、GSM-8K (92.0%)、模拟 Bar Exam Top 10% 等;多模态版本额外评估视觉理解任务。
- 评估设置:多数基准采用 few-shot(5-shot/10-shot/25-shot 依任务);HumanEval 0-shot;GSM-8K 5-shot chain-of-thought。
- 评估指标:Accuracy、F1、pass@k(代码)等任务相关指标。
- 对比基线:GPT-3.5、LLaMA、PaLM、Chinchilla、SOTA 专用模型(如 CodeT+GPT-3.5、Minerva 等);GPT-4 在多数专业/学术基准达到或超越当时 SOTA。
- 医学相关:论文未专门报告医学 benchmark,但 MMLU 含 clinical topics 子集;后续 Med-PaLM 2 等在其基础上扩展医学评估。
摘要(中文)
我们报告 GPT-4 的开发进展,这是一种大规模多模态模型,可接受图像和文本输入并产生文本输出。GPT-4 在多种专业和学术基准上展现人类水平性能,包括模拟律师资格考试取得前 10% 成绩。GPT-4 是基于 Transformer 的预训练模型,经后训练对齐流程提升事实性和行为可控性。本项目的核心组成部分是开发跨尺度可预测的基础设施和优化方法。
3.4 Med-PaLM 2(2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | Toward expert-level medical question answering with large language models |
| 作者与机构 | Karan Singhal, Tao Tu, Juraj Gottweis 等;Google Research |
| 发布时间 | 2024 年 4 月(Nature Medicine) |
| 发布地址 | https://sites.research.google/med-palm/ |
| 论文地址 | https://doi.org/10.1038/s41591-024-03423-7 |
| GitHub 地址 | 无公开代码 |
主要工作与挑战
- 基于 PaLM 2 + 医学领域微调 + ensemble refinement + chain-of-retrieval 构建 Med-PaLM 2。
- MedQA 准确率达 86.5%,较 Med-PaLM 提升 19%+;医生在 9 个临床维度中 8 个更偏好 Med-PaLM 2 回答。
- 挑战:专科医生回答仍整体更优;真实临床工作流验证有限;未集成超声影像。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 医学考试题 / 真实临床问题(文本) | 长形式医学回答 |
实验方法
- 基础模型:PaLM 2 + 医学领域继续预训练与微调(MedQA、MedMCQA、PubMedQA、MMLU clinical 等数据)。
- 推理增强:(1)Ensemble refinement——多候选答案精炼;(2)Chain-of-retrieval——检索增强 grounding,减少幻觉。
- MCQ 评估:MedQA (86.5%)、MedMCQA、PubMedQA、MMLU clinical topics;对比 Med-PaLM(67.6%→86.5%,+19%)。
- 长答案人工评估:9 个临床轴(与 Med-PaLM 框架一致);医生在 8/9 轴更偏好 Med-PaLM 2 回答;65% 专科医生偏好 Med-PaLM 2 优于普通全科医生回答。
- 对抗性评估:新构建 adversarial 数据集探测 LLM 局限(Med-PaLM 2 显著优于 Med-PaLM,P<0.001)。
- 安全性:全科医生与专科医生均认为 Med-PaLM 2 回答安全性与医生相当。
- 对比基线:Med-PaLM、GPT-4、专科/全科医生人类回答。
摘要(中文)
LLM 在医学问答中展现潜力,Med-PaLM 首次在 USMLE 风格题目上超过"及格线",但在长形式回答和真实工作流处理上仍有差距。我们提出 Med-PaLM 2,结合基础 LLM 改进、医学领域微调和 ensemble refinement、chain-of-retrieval 等推理增强策略。Med-PaLM 2 在 MedQA 上达 86.5%,在 MedMCQA、PubMedQA 等数据集上大幅提升。详细人类评估显示,医生在 9 个临床维度中 8 个更偏好 Med-PaLM 2 的回答,安全性与医生回答相当。
框图位置
1 |
1 | ┌─────────────────────────────────────────────────────────┐ |
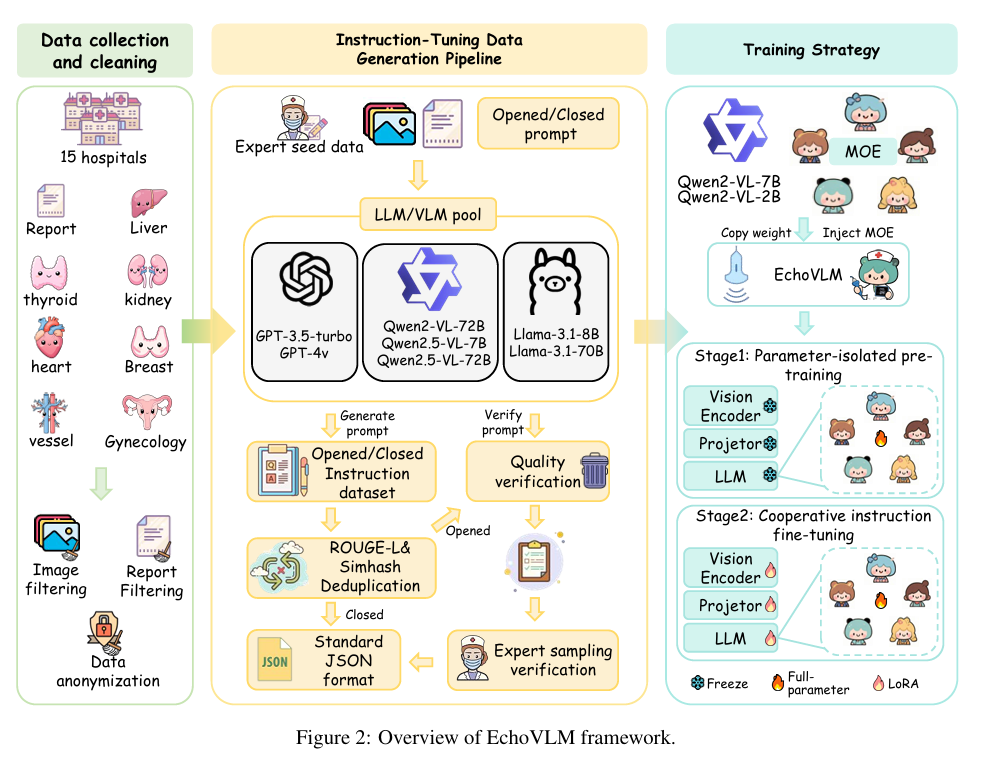
3.5 EchoVLM(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | EchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence |
| 作者与机构 | Chaoyin She, Ruifang Lu, Lida Chen, Wei Wang, Qinghua Huang 等 |
| 发布时间 | 2025 年 9 月 arXiv,2026 年 ACL |
| 发布地址 | https://arxiv.org/abs/2509.14977 |
| 论文地址 | https://arxiv.org/abs/2509.14977 |
| GitHub 地址 | https://github.com/Asunatan/EchoVLM |
主要工作与挑战
- 首个开源 100 亿参数级 超声专用视觉-语言模型,基于 Qwen2-VL + Dual-path MoE 架构。
- 训练数据:208,941 临床病例、147 万关键帧超声图像、180 万指令微调对,覆盖 7 大解剖系统。
- 支持报告生成、诊断预测、视觉问答(VQA)等多任务。
- 挑战:MoE 路由稳定性、vLLM 推理兼容性、跨中心泛化、临床安全性验证。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 超声 B 模图像 + 文本指令(报告/诊断/VQA) | 超声报告文本 / 诊断结论 / VQA 回答 |
实验方法
- 数据集:15 家医院 208,941 病例、147 万关键帧、180 万指令对(7 大解剖系统);held-out 测试集 27,577 图像 + 3,000 报告;补充 OOD 公开数据集(Li et al. 2024b,乳腺/肝/甲状腺)。
- 模型:基于 Qwen2-VL,Dual-path MoE(冻结静态专家 + 1 共享专家 + 4 路由专家 Top-2);EchoVLM 3B / 11B 两版本。
- 两阶段训练:(1)Stage I——仅训 MoE,208,941 报告 + 147 万帧,LR=1e-3;(2)Stage II——LoRA(rank=8)+ MoE 全参数指令微调,180 万样本,LR=2e-5;8×A100-80G,DeepSpeed ZeRO-2,图像 392×392,bf16。
- 评估任务:7 器官 × 3 任务(报告生成、诊断、VQA);greedy decoding。
- 评估指标:BLEU-1、ROUGE-1/L、METEOR、BERTScore;补充实体级 Macro-F1/P/R、Hamming Accuracy。
- 对比基线(11 个,均全参数微调):Qwen2-VL-7B、Qwen2.5-VL、LLaVA-Med、HuatuoGPT-Vision、Lingshu、Medgemma、LLaVA1.5/NeXT/OneVision、Gemma-3 等;较 Qwen2-VL BLEU-1 +7.58、ROUGE-1 +3.45。
摘要(中文)
超声成像是早期癌症筛查的首选模态,但传统诊断高度依赖医师经验,存在主观性强、效率低等挑战。视觉-语言模型(VLM)提供解决思路,但通用模型缺乏超声领域知识,多器官泛化不足。我们提出 EchoVLM,采用覆盖七大解剖区域的 MoE 架构,支持报告生成、诊断和视觉问答。实验表明,EchoVLM 在报告生成任务上 BLEU-1 和 ROUGE-1 分别较 Qwen2-VL 提升 10.15 和 4.77 分,具有提升超声诊断准确性的 substantial 潜力。
框图位置
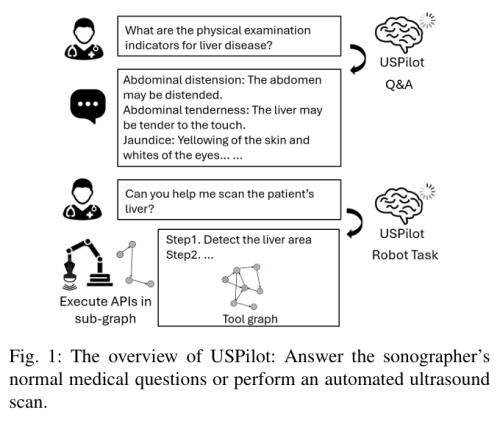
3.6 USPilot(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | USPilot: An Embodied Robotic Assistant Ultrasound System with Large Language Model Enhanced Graph Planner |
| 作者与机构 | Ming Chen, Shuang Fan, Guang-Zhong Cao, Yang Liu, Hong Liu 等 |
| 发布时间 | 2025 年 2 月(arXiv) |
| 发布地址 | https://arxiv.org/abs/2502.12498 |
| 论文地址 | https://arxiv.org/abs/2502.12498 |
| GitHub 地址 | 见论文(待作者公开完整代码) |
主要工作与挑战
- 提出 具身超声机器人系统 USPilot,LLM 微调理解超声领域问答,LLM 增强 GNN 作为任务规划器。
- 可响应患者超声相关查询,根据用户意图自主执行超声扫描流程。
- 挑战:机器人 API 调用可靠性、安全关键场景下的 LLM 幻觉、真实临床验证不足。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 自然语言指令 / 超声相关问题 + 机器人状态 | 任务规划序列 / 机器人动作 API 调用 / 文本回答 |
实验方法
- 系统组成:(1)LLM 微调模块——理解超声领域问答;(2)LLM 增强 GNN 任务规划器——将自然语言意图映射为超声机器人 API 调用序列;(3)具身超声机器人——执行扫描动作。
- LLM 微调:在超声特定问答与任务语料上 fine-tune,使模型理解超声术语、扫描协议与患者交互场景。
- 任务规划评估:在公开机器人任务规划数据集上评估 LLM-enhanced GNN vs 规则基线 vs LLM-only 规划;指标为任务规划准确率(API 序列与 ground truth 匹配)。
- 端到端验证:演示自主理解用户超声意图并执行扫描流程(论文以仿真/原型系统为主,临床大规模验证有限)。
- 对比基线:规则基线规划器、纯 LLM 规划(无 GNN)、无 LLM 微调版本;LLM+GNN 组合在规划准确率上达到论文报告的最优水平。
- 局限说明:超声领域 fine-tune 数据规模仍有限;真实临床环境安全性与可靠性需进一步验证。
摘要(中文)
在大语言模型时代,具身智能为机器人操作任务带来变革性机遇。超声成像应用广泛但专业超声医师全球短缺。我们提出 USPilot,基于 LLM 框架的具身超声机器人辅助系统,可自主执行超声采集。系统作为虚拟超声医师,响应患者超声相关查询并根据用户意图执行扫描。通过 LLM 微调,USPilot 深入理解超声特定问题和任务;LLM 增强的 GNN 管理超声机器人 API 并作为任务规划器。实验表明 LLM 增强 GNN 在公开数据集上达到前所未有的任务规划准确率。
框图位置
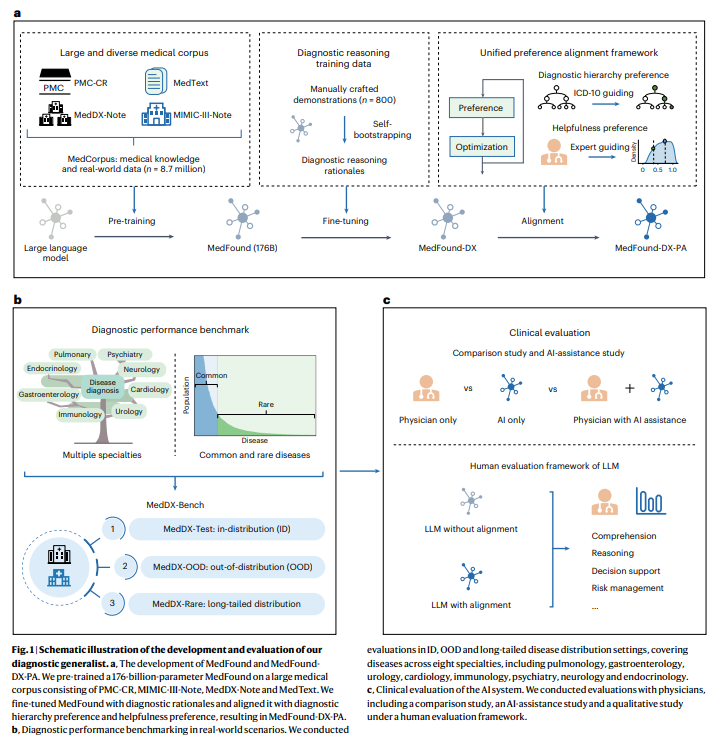
3.7 MedFound(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | A generalist medical language model for disease diagnosis assistance |
| 作者与机构 | Xuehai Liu, Huaxiu Liu, Guan Yang 等 |
| 发布时间 | 2025 年 1 月(Nature Medicine) |
| 发布地址 | https://www.nature.com/articles/s41591-024-03416-6 |
| 论文地址 | https://doi.org/10.1038/s41591-024-03416-6 |
| GitHub 地址 | 无公开代码 |
主要工作与挑战
- 发布 1760 亿参数 通用医学 LLM MedFound,基于大规模医学文本和真实临床记录预训练。
- Chain-of-Thought 自举策略学习医师推断诊断,统一偏好对齐框架对齐临床实践。
- 在 8 个专科的分布内/外/长尾(罕见病)场景均超越基线;8 项临床评估指标全面验证。
- 挑战:超大模型部署成本、超声影像未直接集成、监管审批路径。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 病历文本 / 结构化临床数据 / 诊断问题 | 诊断推理 / 鉴别诊断 / 病历摘要 / 风险评估 |
实验方法
- 模型:MedFound-176B 通用医学 LLM;预训练语料含多样化医学文本 + 真实临床记录(EHR 风格)。
- 微调策略:(1)Chain-of-Thought 自举——学习医师推断诊断的逐步推理;(2)统一偏好对齐框架——对齐标准临床实践与偏好。
- 评估场景:8 个专科;三类分布——分布内(常见病)、分布外(外部验证)、长尾(罕见病)。
- 临床评估框架(8 项指标):病历摘要、诊断推理、鉴别诊断、风险管理等;三种模式——AI vs 医师、AI 辅助医师、纯人类评估。
- 评估指标:诊断 Accuracy;8 项临床能力维度的人工评分;分布内/外/罕见病分层报告。
- 对比基线:GPT-4、专科专用模型、其他医学 LLM;MedFound 在三类分布上均超越基线。
- 局限:176B 部署成本高;输出为辅助决策,需医师最终审核。
摘要(中文)
准确诊断是医疗的关键入口。尽管近期 LLM 在少样本/零样本学习中表现优异,其在临床诊断中的有效性尚未充分验证。我们提出 MedFound,1760 亿参数通用医学语言模型,基于多样化医学文本和真实临床记录预训练。进一步通过 Chain-of-Thought 自举策略微调学习医师推断诊断,并引入统一偏好对齐框架。实验表明 MedFound 在 8 个专科的分布内、分布外和长尾场景中均超越基线。综合临床适用性评估(AI vs 医师、AI 辅助、人类评估框架)显示,MedFound 具有辅助医师诊断的可行性。
框图位置
3.8 AMIE(2025)
| 字段 | 内容 |
|---|---|
| 文章名称 | Towards accurate differential diagnosis with large language models(AMIE) |
| 作者与机构 | Daniel McDuff, Mike Schaekermann, Tao Tu 等;Google Research |
| 发布时间 | 2025 年 4 月(Nature) |
| 发布地址 | https://www.nature.com/articles/s41586-025-08869-4 |
| 论文地址 | https://doi.org/10.1038/s41586-025-08869-4 |
| GitHub 地址 | 无公开代码 |
主要工作与挑战
- 提出 AMIE(Articulate Medical Intelligence Explorer),针对临床诊断推理优化的 LLM。
- 基于 NEJM 临床病理讨论(CPC)真实复杂病例,生成鉴别诊断(DDx)列表。
- 交互式界面下,AMIE 辅助医师的 DDx 质量显著优于传统信息检索工具;Standalone 性能超越 GPT-4。
- 挑战:文本-only 未集成超声影像;对话安全性;真实临床部署监管。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 临床病例描述(文本,可多轮对话) | 排序的鉴别诊断列表 + 推理过程 |
实验方法
- 评估病例:NEJM Clinicopathological Conferences (CPC) 真实复杂病例报告(高诊断难度)。
- 模型 AMIE:针对临床诊断推理优化的 LLM;支持多轮对话式病史采集与 DDx 生成。
- Standalone 评估:AMIE 独立生成排序鉴别诊断列表;指标 Top-1 / Top-10 Accuracy(正确诊断是否在列表中/首位);DDx 列表质量由模型-based 评估与医师评分。
- 人机协作评估:医师使用 AMIE 交互界面 vs 传统信息检索(网络搜索、书籍);对比 DDx 列表质量与正确性;AMIE 辅助显著提升医师 DDx 能力。
- 对比基线:当时 GPT-4、医师 + 检索工具;AMIE standalone DDx 质量显著优于 GPT-4。
- 评估维度:DDx 完整性、排序合理性、推理链清晰度;未集成影像模态(纯文本)。
摘要(中文)
鉴别诊断(DDx)是临床决策的核心认知任务,LLM 为构建交互式诊断工具提供机遇。我们介绍 AMIE,针对临床诊断推理优化的 LLM,为复杂真实医学病例生成 DDx。除独立性能评估外,我们将模型集成至交互界面,评估 AMIE 辅助医师与使用传统检索工具(网络搜索等)的对比。AMIE 在 DDx Top-10/Top-1 准确率上表现优异,DDx 列表质量显著优于当时 GPT-4。更重要的是,AMIE 显著提升了医师的鉴别诊断能力。
3.9 医学 LLM 综合综述(2024)
| 字段 | 内容 |
|---|---|
| 文章名称 | A Survey on Medical Large Language Models: Technology, Application, Trustworthiness, and Future Directions |
| 作者与机构 | Lei Liu, Xiaoyan Yang, Junchi Lei, Yue Shen, Jian Wang, Peng Wei, Zhixuan Chu, Zhan Qin, Kui Ren;浙江大学 / 蚂蚁集团 / 香港中文大学(深圳)等 |
| 发布时间 | 2024 年 6 月(arXiv) |
| 发布地址 | https://arxiv.org/abs/2406.03712 |
| 论文地址 | https://arxiv.org/abs/2406.03712 |
| GitHub 地址 | 无官方代码(综述类文章) |
主要工作与挑战
- 系统追踪 Med-LLM 从通用 LLM 到医学专用应用的演进,涵盖基础技术、应用场景与可信性。
- 梳理 Med-LLM 构建流程(预训练、微调、对齐)、医学任务与数据集、评估方法及代表性模型(Med-PaLM、HuatuoGPT 等)。
- 重点讨论公平性、问责制、隐私保护与鲁棒性等可信 AI 议题,以及临床落地监管框架。
- 挑战:医学数据隐私合规、幻觉与有害输出、多模态(含超声影像)融合、临床工作流集成。
输入 / 输出
| 输入 | 输出 |
|---|---|
| 综述类文章,不涉及具体模型 I/O | Med-LLM 技术路线图、模型清单、评估体系与可信性分析 |
摘要(中文)
随着大语言模型的出现,医学人工智能经历了 substantial 的技术进步与范式转变,LLM 在简化医疗服务和改善患者结局方面展现潜力。本综述追踪 Med-LLM 的最新进展,包括背景、关键发现与主流技术,尤其关注从通用模型到医学专用应用的演进。我们首先深入 Med-LLM 的基础技术,说明通用模型如何逐步适配复杂医学任务;其次调研 Med-LLM 在医疗健康各领域的广泛应用及现有模型清单;同时讨论确保公平性、问责制、隐私和鲁棒性的挑战。我们强调持续审查与开发的必要性,并展望 Med-LLM 未来发展方向,为从业者提供 Med-LLM 优势与局限的全面理解。
框图位置

附录:阅读建议
| 研究方向 | 建议精读顺序 | 与 CONRAD 项目关联 |
|---|---|---|
| 超声图像处理 | 1.2 → 1.3 → 1.4 → 1.5 | 心超视频分割、EF 预测 |
| 3DGS / 重建 | 2.1 → 2.2 → 2.7 → 2.4 → 2.5 | 超声序列 3D 重建、帧插值与网格提取 |
| LLM / 自主性 | 3.9 → 3.5 → 3.6 → 3.2 → 3.8 | 超声报告生成、机器人自主扫查 |